
on
JPA 소개
자바 ORM 표준 JPA 프로그래밍을 공부하고 정리하는 포스트입니다.
JPA 소개
JPA는 Java Persistence API의 줄임말로 자바 진영의 ORM 기술 표준입니다.
ORM이 뭘까요? ORM은 Object-relational mapping, 객체 관계 매핑이라는 뜻이고 여기서 R이 RDB에서의 R입니다.
객체는 객체대로 설계하고, 관계형 데이터베이스는 관계형 데이터베이스대로 설계를 한 다음 중간의 차이를 ORM 프레임워크가 해결(매핑)해주겠다는 것입니다.
대중적인 언어들은 대부분 ORM 기술이 존재합니다. 심지어 요즘은 TypeScript도 Type ORM을 제공합니다.
물론 JPA라는 것이 마법을 부리는 것은 아닙니다. 애플리케이션과 JDBC 사이에서 동작을 하면서 개발자는 직접 JDBC API를 사용하는게 아닌 JPA에게 명령을 하면 JPA는 JDBC API를 사용해서 SQL을 보내고 결과를 받아서 전달하는 식으로 동작을 하게 됩니다.
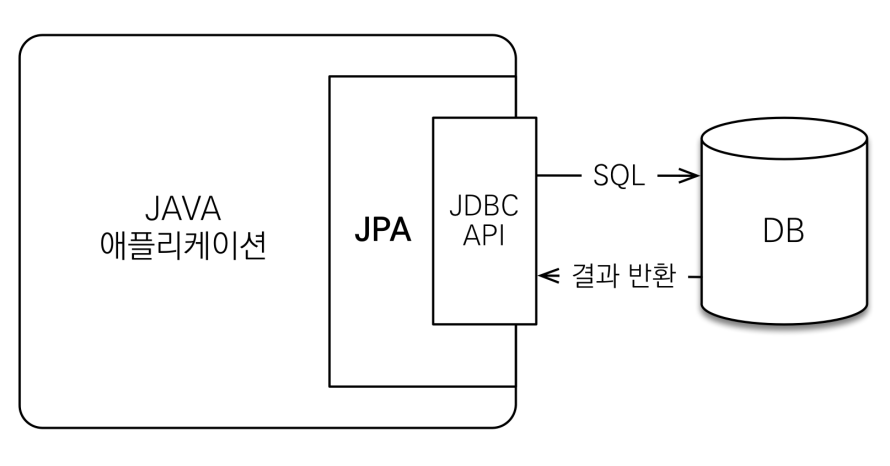
JPA 동작 - 저장
그러면 JPA는 어떻게 동작을 할까요? 예를 들어 다음과 같이 MemberDAO에서 객체를 저장하고 싶다고 생각해보겠습니다.
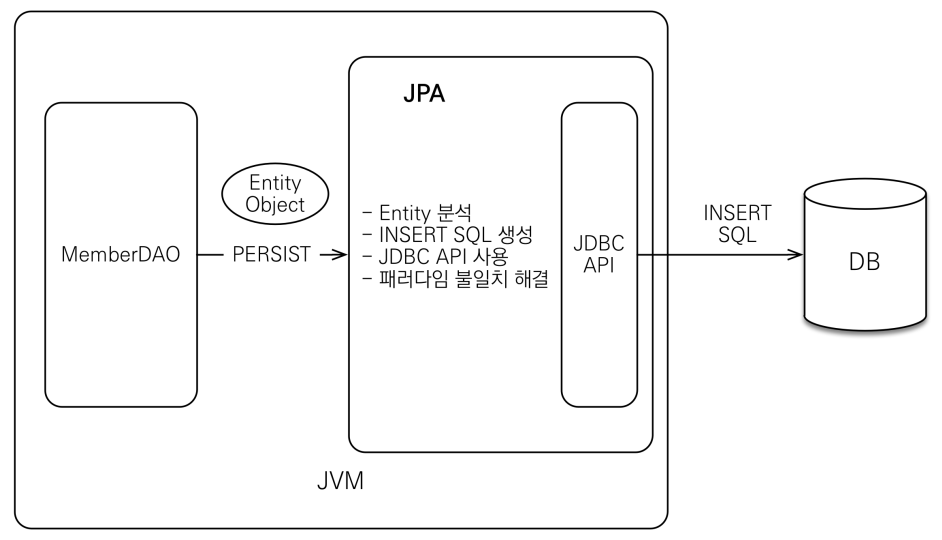
과거에는 JDBC API나 Mybatis 등을 썼다면 JPA의 경우 JPA에게 객체를 넘깁니다. 그러면 JPA가 객체를 분석하고 쿼리를 생성한 후 JDBC API를 사용해서 쿼리를 전달합니다. JPA가 엄청난 마법을 부리는게 아니라 쿼리를 대신 만들어주는 것입니다. 그리고 결과를 받습니다.
여기서 진짜 중요한 것은 패러다임의 불일치를 해결해주는 것입니다.
JPA 동작 - 조회
조회할 때도 마찬가지로 DAO는 PK 값만 넘기고 JPA가 쿼리를 생성하고 결과를 받은 다음 결과를 객체에 매핑해줍니다. JPA가 번잡한 일을 다 해주는 것입니다. 여기서도 마찬가지로 진짜 중요한 것은 패러다임의 불일치를 해결해준다는 것입니다.
JPA 역사
과거에는 EJB, Entity Bean이라는 과거 자바 표준으로 사용하던 것이 있었습니다. 이 EJB에는 문제가 있었는데 기술이 너무 아마추어스러웠습니다. 코드도 지저분하고, 인터페이스를 너무 많이 구현해야되고, 속도도 느리고 심지어 기능도 잘 동작하지 않았습니다.
그래서 거의 사용되지 않았는데, 이것을 사용하던 ‘Gavin King’이라는 분이 새롭게 ORM 프레임워크를 만들어냈는데 그것이 바로 Hibernate입니다. 이렇게 개발된 Hibernate에 많은 개발자들이 동참하여 오픈소스화가 되면서 EJB는 완전히 망했습니다.
Hibernate가 떠오르면서 자바 진영에서 반성을 하고 ‘Gavin King’을 섭외해서 Hibernate를 거의 복사 붙여넣기 수준으로 해서 만들어 낸 것이 JPA입니다.
이렇게 만들어진 JPA는 사실 인터페이스의 모음입니다. JPA의 코드를 살펴보면 인터페이스 밖에 없습니다. 이 JPA 스펙을 구현한 구현체가 3가지 있는데
- Hibernate
- EclipseLink
- DataNucleus
입니다. 거의 대부분 Hibernate를 사용한다고 생각하면 됩니다.
JPA 버전
JPA 1.0(JSR 220) 2006년 : 초기 버전. 복합 키와 연관관계 기능이 부족 JPA 2.0(JSR 317) 2009년 : 대부분의 ORM 기능을 포함, JPA Criteria 추가 JPA 2.1(JSR 338) 2013년 : 스토어드 프로시저 접근, 컨버터(Converter), 엔티티 그래프 기능이 추가
왜 JPA를 사용해야 하는가?
그러면 JPA를 왜 사용해야 할까요? 다음과 같은 이유들이 있는데 하나씩 살펴보겠습니다.
- SQL 중심적인 개발에서 객체 중심으로 개발
- 생산성
- 유지보수
- 패러다임의 불일치 해결
- 성능
- 데이터 접근 추상화와 벤더 독립성
- 표준
SQL 중심적인 개발에서 객체 중심으로 개발
SQL 중심적인 개발의 문제점은 이전 글을 참고하시면 됩니다.
생산성
생산성적인 측면에서 JPA로 CRUD를 하는 것은 아래의 내용이 전부입니다.
- 저장 : jpa.persist(member)
- 조회 : Member member = jpa.find(memberId)
- 수정 : member.setName(“변경할 이름”)
- 삭제 : jpa.remove(member)
코드가 다 만들어져 있습니다. jpa.persist, jpa.find, jpa.remove와 같이 만들어진 것을 가져와서 사용하기만 하면 됩니다. 특히 수정의 경우 setName을 사용하면 jpa에서 update 쿼리를 사용해줍니다!
이처럼 JPA를 사용한다는 것은 마치 Java Collection에 데이터를 넣었다 빼는 것처럼 사용할 수 있게 만든 것입니다. 컬렉션에서 객체를 꺼내서 값을 변경한 후에 컬렉션에 다시 넣나요? 안 넣습니다. 이처럼 JPA에서는 컬렉션에서 가져와서 사용하는 것처럼 DB를 사용할 수 있게 만들어줍니다.
유지보수
유지보수 측면에서는 기존에는 필드 변경 시 모든 SQL을 수정해야했습니다. JPA를 사용하면 필드만 추가하면 되고, SQL은 JPA가 알아서 처리해줍니다.
패러다임의 불일치 해결
JPA가 정말 대단한 것은 관계형 데이터베이스와 객체의 패러다임의 불일치를 해결해주는 것입니다.
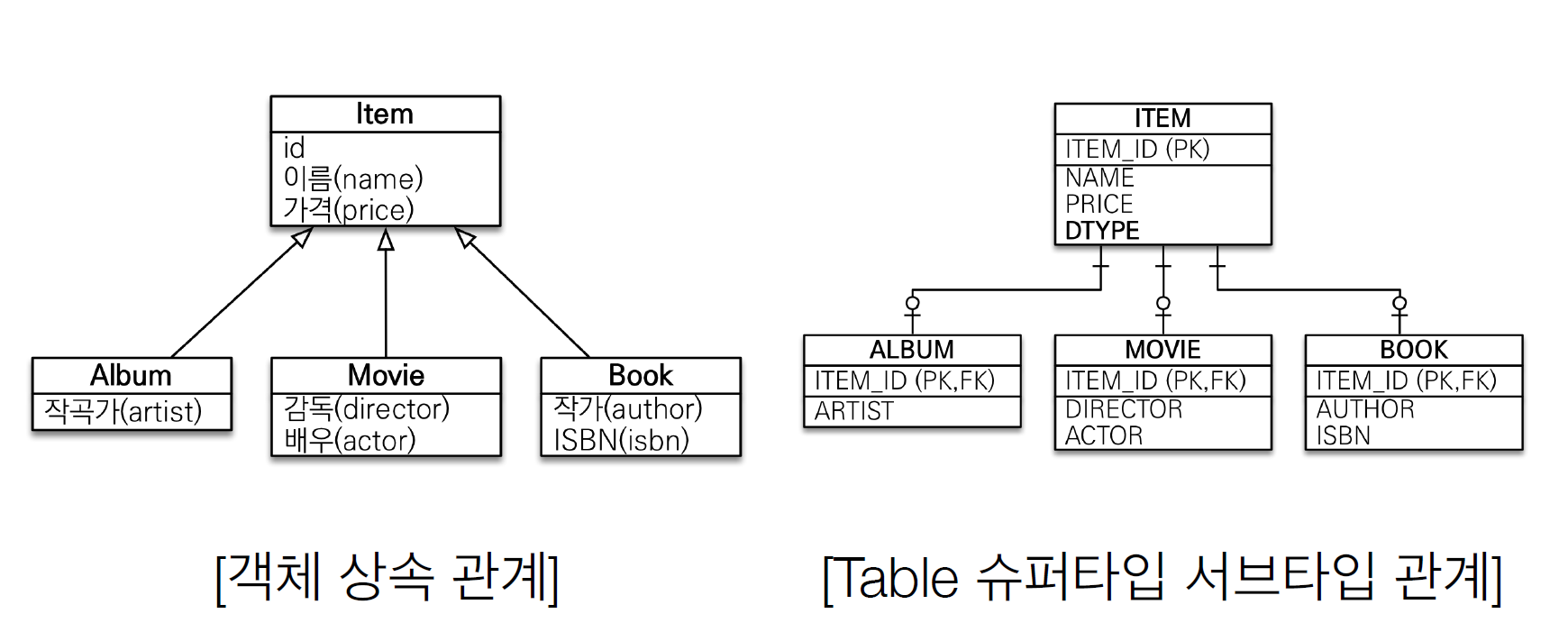
먼저 상속 관계는 슈퍼타입 서브타입 관계를 정규화되게 잘 모델링해서 만든 다음 DB에 넣을 때 Item 객체는 Item 테이블에, Album 객체는 Album 테이블에 들어가야 합니다.
이것을 JPA를 사용하면 기가 막히게도 알아서 나눠서 넣어줍니다.
- 개발자가 할 일
jpa.persist(album);
- 나머진 JPA가 처리
INSERT INTO ITEM ...INSERT INTO ALBUM ...
조회할 때는 더 기가막히게 처리해줍니다. Album을 조회하고 싶어서 PK 값을 넘기면 Item과 Album을 Join해서 가져옵니다. 만약 Movie를 가져오고 싶으면, 알아서 Join해서 가져와줍니다.
- 개발자가 할 일
Album album = jpa.find(Album.class, albumId);
- 나머진 JPA가 처리
SELECT I.*, A.* FROM ITEM I JOIN ALBUM A ON I.ITEM_ID = A.ITEM_ID
이렇게 패러다임의 불일치를 JPA가 중간에서 다 처리해줍니다.
연관관계, 객체 그래프 탐색
예를 들어서, member에 새로운 team을 세팅한 다음 member를 저장해보겠습니다.
member.setTeam(team);
jpa.persist(member);
이렇게 DB에 저장이 된 후에 JPA에서 find로 member를 가져온 다음, getTeam으로 team을 꺼내올 수 있습니다. 마치 자바 컬렉션에 넣은 것처럼.
Member member = jpa.find(Member.class, memberId);
Team team = member.getTeam();
신뢰할 수 있는 엔티티, 계층
class MemberService {
...
public void process() {
Member member = memberDAO.find(memberId);
member.getTeam();
member.getOrder().getDelivery();
}
}
기존 SQL을 사용할 때는 memberDAO 내부에서 어떤 쿼리가 발생했는지 알 수 없기 때문에 엔티티를 신뢰할 수 없다고 했었습니다.
하지만 JPA를 통해서 객체를 가져왔다면 객체 그래프를 자유롭게 사용할 수 있습니다.
JPA에는 지연 로딩(Lazy Loading)이라는 기능이 있어서 관련 객체를 조회해서 사용하는 시점에 쿼리를 날려서 데이터를 가져오기 때문에 자유롭게 객체 그래프를 탐색할 수 있습니다. 즉, 신뢰할 수 있다는 것입니다.
JPA와 비교하기
String memberId = "100";
Member member1 = list.get(memberId);
Member member2 = list.get(memberId);
member1 = member2;
JPA에서는 자바 컬렉션에서 한 것처럼 조회한 것처럼 동일한 트랙잭션에서 조회한 엔티티는 같음을 보장해줍니다.
JPA의 성능 최적화 기능
항상 계층 사이에 중간 계층이 있으면, 예를 들어 CPU와 메모리 사이에 캐시 레벨이 있어서 가능한 것처럼, 모아서 쓰는 버퍼링과 읽을 때 캐싱을 할 수 있습니다.
즉, 단순히 SQL을 쓰는 것 보다 JPA를 잘 사용하면 성능을 끌어올릴 수 있습니다.
- 1차 캐시와 동일성 보장 - 캐싱
같은 트랜잭션 안에서는 같은 엔티티를 반환한다고 했습니다. 만약 비즈니스 레벨이 복잡해서 중간에 같은 것을 계속 조회하는 로직이 있을 때, 같은 Id를 조회하면 JPA의 경우 SQL을 한 번만 실행하고 이후에 조회에서는 캐싱된 데이터를 사용합니다.
String memberId = "100";
Member m1 = jpa.find(Member.class, memberId); // SQL
Member m2 = jpa.find(Member.class, memberId); // 캐시
println(m1 == m2); // true
하지만 여기서 캐시는 우리가 알고 있는 그 캐시는 아닙니다. 트래픽 요청이 와서 발생한 트랙잭션이 끝나기까지의 사이에서 동일성을 보장하기 때문에 굉장히 짧은 시간입니다.
- 트랜잭션을 지원하는 쓰기 지연
트랜잭션을 커밋하기까지 똑같은 쿼리가 반복될 때 작성한 SQL을 모아서 마지막에 한 번에 모아서 전송하는 JDBC Batch라는 기능이 있습니다. 그런데 이 기능을 사용하면 코드가 지저분합니다.
하지만 JPA에서 옵션을 하나만 사용하면 아래와 같이 깔끔하게 만들 수 있습니다.
transaction.begin(); // 트랜잭션 시작
em.persist(memberA);
em.persist(memberB);
em.persist(memberC);
/* INSERT SQL을 DB에 전송하지 않음 */
/* 커밋하는 순간 INSERT SQL 모아서 전송 */
transaction.commit(); // 트랜잭션 커밋
JPA는 메모리에 쌓아두었다가 커밋되는 순간 한 방에 Batch를 사용해서 입력할 수 있습니다. 개발자는 디테일한 코드를 신경쓰지 않아도 됩니다.
지연 로딩과 즉시 로딩

지연 로딩은 객체가 실제 사용될 때 쿼리를 날려서 가져오는 방식입니다. 처음 member 객체를 로딩할 때 team 객체는 가져오지 않고 member 객체만 가져오고 이 후에 team 객체가 사용될 때 team 객체를 호출합니다.

지연 로딩은 사용할 때마다 쿼리가 발생하게 되서 네트워크를 매번 타야됩니다. 만일 member를 사용할 때 team을 무조건 사용한다면, 같이 가져오는게 훨씬 이득입니다. 그렇기 때문에 연관된 객체까지 한 번에 가져오는 방식이 즉시 로딩입니다.
물론, 각각 따로 사용하는 경우가 많다면 지연 로딩을 사용하는 것이 좋습니다.
ORM은 객체와 RDB 두 기둥 위에 있는 기술입니다. 이게 무슨 말일까요? JPA만 잘 안다고해서 잘 할 수 있는게 아니고, RDB만 잘 한다고 잘 할 수 있는게 아닙니다. 기술 사이에서 밸런스를 맞추는게 중요합니다.
Comments
JPA 의 다른 글
-
엔티티 매핑 2부 28 Jan 2022
-
엔티티 매핑 1부 22 Jan 2022
-
영속성 관리 - 내부 동작 방식 2부 18 Jan 2022
-
영속성 관리 - 내부 동작 방식 1부 18 Jan 2022
-
애플리케이션 개발 17 Jan 2022
-
JPA 소개 15 Jan 2022
-
JPA 시작하기 07 Nov 2021