
on
자료구조와 알고리즘의 이해
자료구조
자료구조란?
프로그램이란 데이터를 표현하고, 그렇게 표현된 데이터를 처리하는 것이다. 여기서 데이터의 표현은 데이터의 저장을 포함하는 개념이고, 이 데이터의 저장을 담당하는 것이 자료구조(data structure)이다.
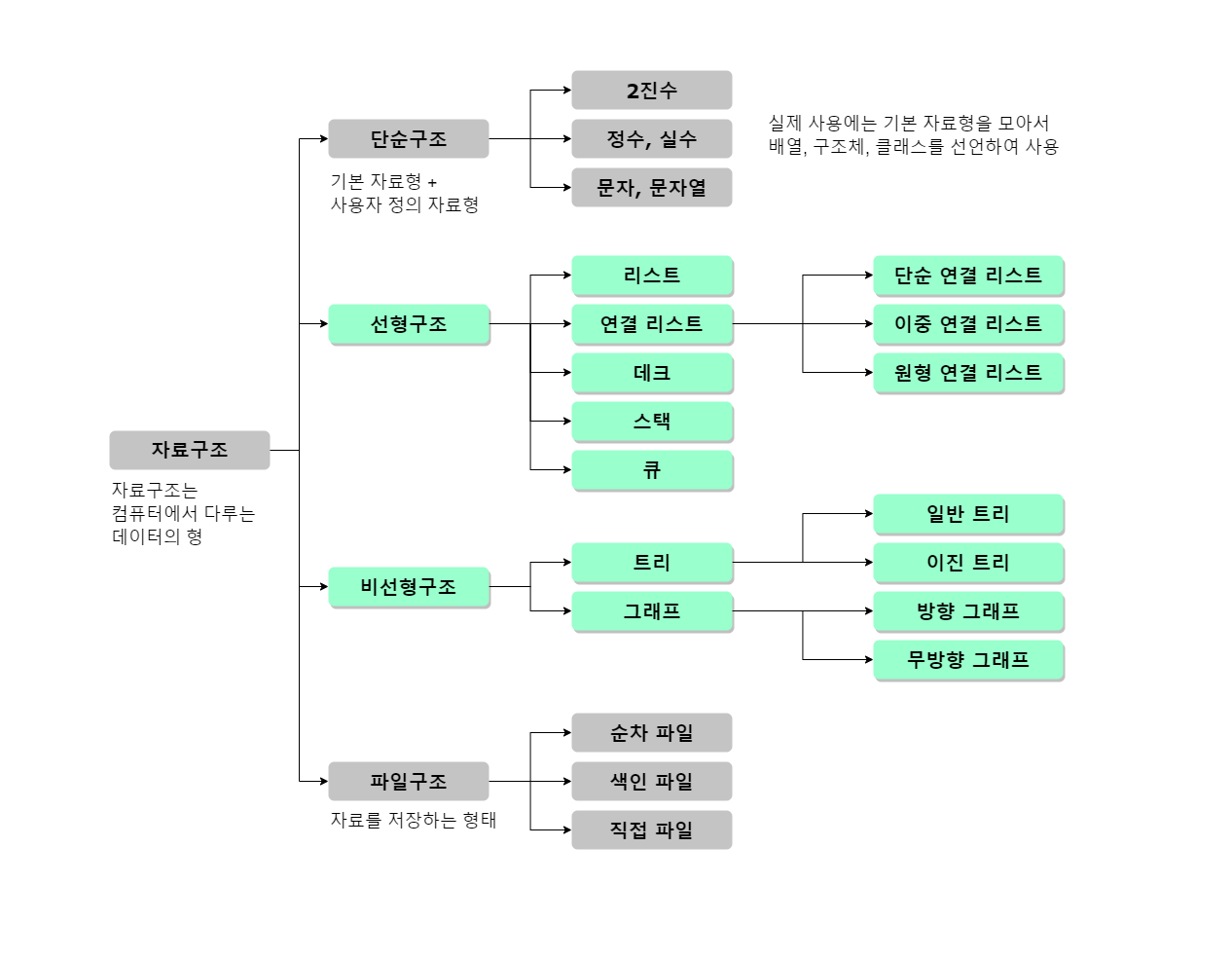
선형구조는 자료를 표현 및 저장하는 방식이 선형(linear)이다. 데이터를 선의 형태로 나란히 혹은 일렬로 저장하는 방식이다. 비선형구조는 이름처럼 데이터를 나란히 저장하지 않는 구조이다.
자료구조와 알고리즘
자료구조가 ‘데이터의 표현 및 저장방법’이라면, 알고리즘은 표현 및 저장된 데이터를 대상으로 하는 문제의 해결방법을 뜻한다. 어떠한 배열이 있고 그 배열에 저장된 값을 더하는 반복문이 있다면 배열을 선언하는 것은 자료구조적 측면의 코드이고 반복문의 구성은 알고리즘적 측면의 코드이다. 즉, 반복문은 배열에 저장된 모든 값의 합을 구하는 알고리즘이라 할 수 있다.
시간 복잡도(Time Complexity)와 공간 복잡도(Space Complexity)
알고리즘을 평가하는 두 가지 요소는 다음과 같다.
-
어떤 알고리즘이 어떠한 사황에서 더 빠르고 더 느린가
-
어떤 알고리즘이 어떠한 상황에서 메모리를 적게 쓰고 많이 쓰는가
하나는 ‘속도’에 관한 것이고 다른 하나는 ‘메모리의 사용량’에 관한 것인데, 속도에 해당하는 알고리즘의 수행시간 분석결과를 시간 복잡도(time Complexity)라 하고, 메모리 사용량에 대한 분석결과를 공간 복잡도(space complexity)라 한다.
메모리를 적게 쓰고 속도도 빠른 것이 최적의 알고리즘이지만, 일반적으로 메모리 사용량보다 실행속도에 초점을 두고 평가한다. 특정 알고리즘에 대한 상대적 우월성을 입증해야 하는 경우에는 메모리의 사용량도 함께 고려하지만 검증이 끝난 알고리즘의 적용을 고려하는 경우에는 속도에 초점을 두어 적합성 여부를 판단하게 된다.
알고리즘의 수행속도를 평가할 때는 다음과 같은 방식을 취한다.
- 연산의 횟수를 센다.
- 처리해야할 데이터의 수 n에 대한 연산횟수의 함수 T(n)을 구성한다.
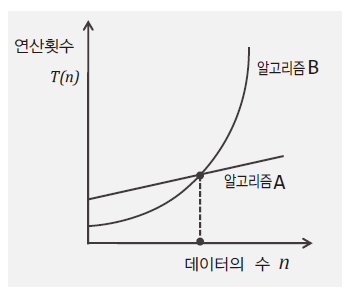
연산의 횟수를 통해서 알고리즘의 빠르기를 판단하므로 연산의 횟수가 적어야 빠른 알고리즘이다. 그리고 데이터의 수 n에 대한 연산횟수의 함수 T(n)을 구성한다는 것은 데이터의 수를 함수에 입력하면 연산의 횟수가 바로 계산 되는 식을 구성한다는 뜻이다.
알고리즘 별 연산횟수를 함수 T(n)의 형태로 구성하면, 그래프를 통해서 데이터 수의 변화에 따른 연산횟수의 변화 정도를 파악할 수 있으며, 둘 이상의 알고리즘을 비교하기가 용이해진다.
순차 탐색(Linear Search) 알고리즘과 시간 복잡도 분석의 핵심요소
for(int i = 0; i < length; i++) {
if(arr[i] == target)
return i;
}
위 코드는 순차 탐색 알고리즘인데, 알고리즘의 시간 복잡도를 계산하기 위해서는 핵심이 되는 연산이 무엇인지 잘 판단해야 한다. 위 코드에서 핵심 연산은 == 연산으로 동등비교 수행횟수가 줄어들면 나머지 연산의 횟수도 자동으로 줄어든다.
순차 탐색 알고리즘은 운이 좋으면 배열의 맨 앞에서 대상을 찾아서 수행 횟수가 1이 되고 운이 좋지 않아 배열의 맨 끝에서 찾거나 찾고자 하는 값이 없으면 수행 횟수가 n이 된다. 이 두 경우를 각각 ‘최선의 경우(best case)’와 ‘최악의 경우(worst case)’라 한다.
알고리즘을 평가하는데 있어서 최선의 경우는 관심대상이 아니다. 데이터 수가 많아질 경우 알고리즘 별로 ‘최악의 경우’에 수행하게 되는 연산의 횟수가 큰 차이를 보인다. 따라서 알고리즘의 성능을 판단하는데 있어 중요한 것은 ‘최악의 경우’이다.
순차 탐색 알고리즘 시간 복잡도 : 최악의 경우
데이터의 수가 $n$개일 때, 최악의 경우에 해당하는 연산횟수(비교연산 횟수)는 $n$이다.
- $T(n) = n$ 최악의 경우를 대상으로 정의한 함수 $T(n)$
이진 탐색(Binary Search) 알고리즘
순차 탐색보다 훨씬 좋은 성능을 보이는 이진 탐색 알고리즘은 배열에 적용하기 위해서 배열에 저장된 데이터는 정렬되어 있어야 한다. 즉, 이진 탐색 알고리즘은 정렬된 데이터가 아니면 적용이 불가능하다.(정렬의 기준 및 방식과는 관계없다.)
길이가 9인 배열 arr[] = {1, 2, 3, 7, 9, 12, 21, 23, 27} 있다고 가정했을 때, 숫자 3이 저장되어 있는지 확인하는 이진 탐색 알고리즘은 다음과 같이 동작한다.
- 배열 인덱스의 시작과 끝이 각각 0과 8이다.
- 0과 8을 합하여 그 결과를 2로 나눈다.
- 2로 나눠 얻은 결과 4를 인덱스 값으로 하여 arr[4]에 저장된 값을 확인한다.
배열의 중앙에, 찾는 값이 저장되어 있는지 확인하는 것이 이진 배열의 첫 번째 시도이다. arr[4]에 3이 저장되어 있지 않으므로 두 번째 시도를 진행한다.
- arr[4]의 값과 탐색 대상의 대소를 비교한다. (9 > 3)
- arr[4] > 3 이므로 탐색의 범위 인덱스를 0 ~ 3으로 제한한다.
- 0과 3을 더한 값을 2로 나누고 나머지는 버린다.
- 1을 얻었으니 arr[1]을 확인한다.
첫 번째 시도가 실패했을 경우 두 번째 시도에서 탐색 범위가 반으로 줄어든다. 이는 배열에 데이터가 정렬되어 있기 때문에 가능한 것이며, 이진 탐색 알고리즘의 핵심이다. 두 번째 시도 이후에는 탐색 대상을 찾을 때까지 동일한 패턴을 반복한다.
이처럼 이진 탐색 알고리즘은 탐색의 대상을 반복해서 반씩 줄여나가는 알고리즘이다. 때문에 순차 탐색 알고리즘에 비해 좋은 성능을 보인다.
이진 탐색 알고리즘의 구현
이진 탐색 알고리즘은 시작 인덱스와 끝 인덱스가 서로 만난다고 끝나는 것이 아니다. 시작 인덱스와 끝 인덱스가 같다는 것은 탐색 대상이 하나 남았다는 것을 뜻하기 때문이다. 따라서 이진 탐색 알고리즘은 다음과 같은 형태로 반복문이 구성된다.
while(first <= last) { // first는 시작 인덱스, last는 끝 인덱스
...
}
즉, 시작 인덱스가 끝 인덱스보다 큰 경우 탐색이 종료되는 것이다. 그리고 이 경우에는 탐색이 실패한 것이다.
탐색 대상을 반으로 줄이는 연산에서 한 가지 주의해야 하는데, first나 last의 값을 새롭게 지정해 줄 때 중앙 값 mid에서 1을 더하거나 빼서 변수에 저장해야 한다. 그렇지 않을 경우 first가 last보다 커지지 못한 채 무한루프에 빠지게 된다.
이진 탐색 알고리즘 시간 복잡도 : 최악의 경우
데이터의 수가 $n$개일 때, $n$이 1이 되기까지 2로 나눈 횟수(비교연산 횟수)는 $k$이고 데이터가 1개 남았을 때 마지막 비교연산 1회를 진행한다.
- 시간 복잡도 함수 $T(n) = k + 1$
$k$를 $n$에 관한 식으로 바꿔서 정리하면 $k = log_{2}\,n$이 된다. 따라서
- 시간 복잡도 함수 $T(n) = log_{2}\,n$
+1이 없는 이유는 데이터의 수 $n$이 증가함에 따라서 비교연산의 횟수가 로그적(logarithmic)으로 증가하고, $T(n)$을 구성하는 이유는 데이터 수의 증가에 따른 연산횟수의 변화 정도를 판단하는 것이기 때문이다.
빅-오 표기법(Big-Oh Notation)
$T(n) = n^2$을 빅-오 표기법으로 표현하면 $O(n^2)$이 된다. $T(n)$이 다항식으로 표현된 경우, 최고차항의 차수가 빅-오가 된다.
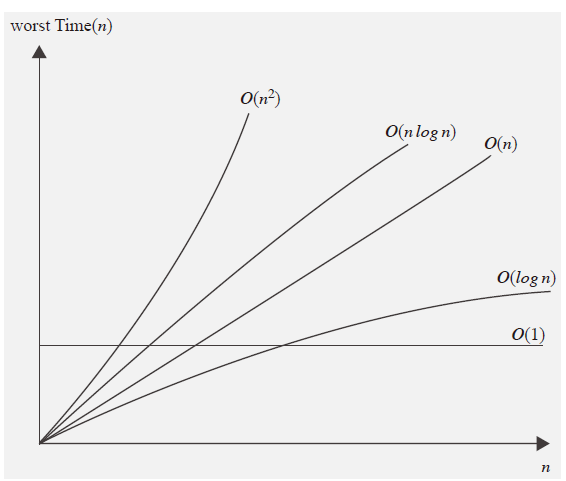
다음은 대표적인 빅-오 표기들이다.
- $O(1)$ : 상수형 빅-오. 연산횟수가 고정인 유형의 알고리즘을 대표한다.
- $O(log\,n)$ : 로그형 빅-오. 데이터 수의 증가율에 비해서 연산횟수의 증가율이 훨씬 낮은 알고리즘을 의미한다.
- $O(n)$ : 선형 빅-오. 데이터의 수와 연산횟수가 비례하는 알고리즘을 의미한다.
- $O(n\,log\,n)$ : 선형로그형 빅-오. 데이터의 수가 두 배로 늘 때, 연산횟수는 두 배 조금 넘게 증가하는 알고리즘을 의미한다.
- $O(n^2)$ : 데이터 수의 제곱에 해당하는 연산횟수를 요구하는 알고리즘을 의미한다. 이중으로 중첩된 반복문 내에서 알고리즘에 관련된 연산이 진행되는 경우에 발생한다.
- $O(n^3)$ : 데이터 수의 세 제곱에 해당하는 연산횟수를 요구하는 알고리즘을 의미한다. 삼중으로 중첩된 반복문 내에서 알고리즘에 관련된 연산이 진행되는 경우에 발생한다.
- $O(2^n)$ : 지수형 빅-오. 비현실적인 알고리즘으로 ‘지수적 증가’라는 매우 무거운 연산횟수의 증가를 보인다.
빅-오 표기들의 성능(수행시간, 연산횟수)의 대소를 비교하면 다음과 같다.
$O(1)\,<\,O(log\,n)\,<\,O(n)\,<\,O(n\,log\,n)\,<\,O(n^2)\,<\,O(n^3)\,<\,O(2^n)$
Comments
DATA STRUCTURE 의 다른 글
-
리스트 04 Nov 2020
-
재귀 01 Nov 2020
-
자료구조와 알고리즘의 이해 30 Oct 2020