
on
3주차 과제: 연산자.
해당 글을 백기선 님의 자바 스터디 3주차 과제를 공부하고 공유하기 위해서 작성되었습니다.
목표
자바가 제공하는 다양한 연산자를 학습한다.
학습할 것
- 산술 연산자
- 비트 연산자
- 관계 연산자
- 논리 연산자
- instanceof
- assignment(=) operator
- 화살표(->) 연산자
- 3항 연산자
- 연산자 우선 순위
- Java 13. switch 연산자
연산자(operator)
연산자는 연산을 수행하는 기호를 말한다. 우리가 흔히 수학에서 배웠던 사칙연산(+, -, *, /)을 비롯해서 다양한 연산자가 존재한다.
연산자가 연산을 수행하기 위해서는 반드시 연산의 대상이 있어야 하는데, 이를 피연산자(operand)라고 한다. 피연산자로 상수, 변수 또는 식(계산식) 등을 사용할 수 있다.
대부분의 연산자는 두 개의 피연산자를 필요로 하며, 하나 또는 세 개의 피연산자를 필요로 하는 연산자도 있다. 연산자는 피연산자로 연산을 수행하고 나면 항상 결과값을 반환한다.
연산자의 종류
연산자를 크게 4가지로 분류하면 산술, 비교, 논리, 대입으로 나눌 수 있다.
| 종류 | 연산자 | 설명 |
| 산술 연산자 | + - * / % << >> | 사칙 연산(+, -, *, /)과 나머지 연산(%) |
| 비교 연산자 | > < >= <= == != | 크고 작음과 같고 다름을 비교 |
| 논리 연산자 | && || ! & | ^ ~ | '그리고(AND)'와 '또는(OR)'으로 조건을 연결 |
| 대입 연산자 | = | 우변의 값을 좌변에 저장 |
| 기 타 | (type) ? : instanceof | 형변환 연산자, 3항 연산자, instanceof연산자 |
피연산자의 개수에 의한 분류
피연산자의 개수로 연산자를 분류하기도 하는데, 피연산자의 개수가 하나면 ‘단항 연산자’, 두 개면 ‘이항 연산자’, 세 개면 ‘삼항(3항) 연산자’라고 부른다. 대부분의 연산자는 ‘이항 연산자’이고, 삼항 연산자는 오직 ? : 하나 뿐이다.
서로 다른 연산자의 기호가 같은 경우가 있는데, 이럴 때는 피연산자의 개수로 구분이 가능하다.
- 3 - 5
위의 경우 -가 두 개 포함되어 있는데, 왼쪽의 것은 부호 연산자이고 오른쪽의 것은 뺄셈 연산자이다. 부호 연산자는 단항 연산자이므로 바로 뒤에 있는 ‘3’만 피연산자이고, 뺄셈 연산자는 이항 연산자로 피연산자가 ‘-3’과 ‘5’ 두 개이다.
피연산자의 개수별로 나누어 분류하는 것은 연산자의 우선순위와도 관련이 있다.
식과 대입 연산자
연산자와 피연산자를 조합하여 계산하고자 하는 바를 표현한 것을 식(expression)이라고 한다. 식을 계산하여 결과를 얻는 것을 식을 평가(evaluation)한다고 하는데 하나의 식을 평가(계산)하면, 단 하나의 결과를 얻는다.
프로그래밍에서는 작성한 식을 프로그램에 포함시키려면, 식의 끝에 ;을 붙여서 문장으로 만들어야 한다.
예를 들어 2 * x + 5라는 식을 문장으로 만들려면 2 * x + 5;처럼 하면된다.
위 문장에서 변수 x의 값이 5일 때, 문장은 다음과 같은 과정으로 처리된다.
2 * x + 5;
-> 2 * 5 + 5;
-> 15; // 결과를 얻었으나 사라진다.
식이 평가되어 15라는 결과를 얻었지만, 이 값은 어디에도 쓰이지 않고 사라지기 때문에 이 문장은 아무런 의미가 없다. 그래서 대입 연산자 =를 사용해서 변수와 같이 값을 저장할 수 있는 공간에 결과를 저장해야 한다.
y = 2 * x + 5;
-> y = 2 * 5 + 5;
-> y = 15; // y에 15라는 평가결과가 저장된다.
이 후 변수 y에 저장된 값을 다른 곳에 사용하거나 출력함으로써 의미있는 결과를 얻을 수 있다.
int y = 2 * x + 5;
System.out.println(y);
만일 평가결과만을 원하고 이 값이 다른 곳에 쓰이지 않을 것이라면 변수에 저장하지 않고 println 메서드의 괄호 안에 직접 식을 작성해도 된다.
산술 연산자
산술 연산자에는 사칙 연산자 +, -, *, /와 나머지 연산자 %가 있다.
사칙 연산자
사칙 연산자, 덧셈(+), 뺄셈(-), 곱셈(*), 나눗셈(/)은 자주 사용되는 연산자이다. 곱셈, 나눗셈, 그리고 나머지 연산자가 덧셈, 뺄셈연산자보다 우선순위가 높으므로 먼저 처리된다.
사칙연산을 수행하고 결과 값을 확인해보면 나눗셈의 경우 소수점 이하가 버려지는 것을 확인할 수 있다. 이는 나누기 연산자의 피연산자가 모두 int 타입인 경우, 연산결과 또한 int 타입이 되기 때문이다. 그래서 실제 연산결과에 소수점 이하가 있더라도 버려지고 정수만 남는 것이다. 이 때 반올림은 발생하지 않는다.
소수점 이하의 결과 값을 포함한 연산결과를 얻기 위해서는 두 피연산자 중 어느 한 쪽을 실수형으로 형변환해야 한다. 그래야만 다른 한 쪽도 같이 실수형으로 자동 형변환되어 실수형 값을 결과로 얻을 수 있다.
public class App {
public static void main(String[] args) {
int num = 10;
float num2 = 4.0f;
System.out.println(num / num2);
}
}
위의 코드를 실행하여 결과를 확인하면 2.5가 나온다. 두 피연산자의 타입이 일치하지 않으므로 int 타입보다 범위가 넓은 float 타입으로 일치시킨 후 연산을 수행한 것이다.
피연산자가 정수형인 경우, 나누는 수로 0을 사용할 수 없다. 0으로 나눌 경우 에러가 발생하게 된다.
public class App {
public static void main(String[] args) {
double num_D = 100;
double zero_D = 0;
double result_D = num_D / zero_D;
double result_D2 = num_D % zero_D;
System.out.println("double : 100 / 0 = " + result_D);
System.out.println("double : 100 % 0 = " + result_D2);
int num = 100;
int zero = 0;
int result = num / zero;
int result2 = num % zero;
System.out.println("int : 100 / 0 = " + result);
System.out.println("int : 100 % 0 = " + result2);
}
}
위와 같은 코드를 실행하였을 때 결과는 아래와 같이 나왔다.

컴파일은 정상적으로 되지만 실수형의 경우 나누기 연산자는 Infinity를, 나머지 연산자는 NaN을 결과 값으로 출력했다. 정수형의 경우 ArithmeticException이 발생한다.
Infinity는 말그대로 무한대를 표현하고 NaN은 Not a Number를 뜻한다.
이러한 문제를 해결하기 위해서는 BigDecimal 클래스를 사용하거나 try문을 사용하면 된다고 한다.
우리는 흔히 int 형을 사용하여 연산을 많이 하는데 byte 형의 경우 어떻게 될까?
byte a = 10;
byte b = 20;
byte c = a + b;
System.out.println(c);
위의 코드를 컴파일 할 경우 에러가 발생한다.
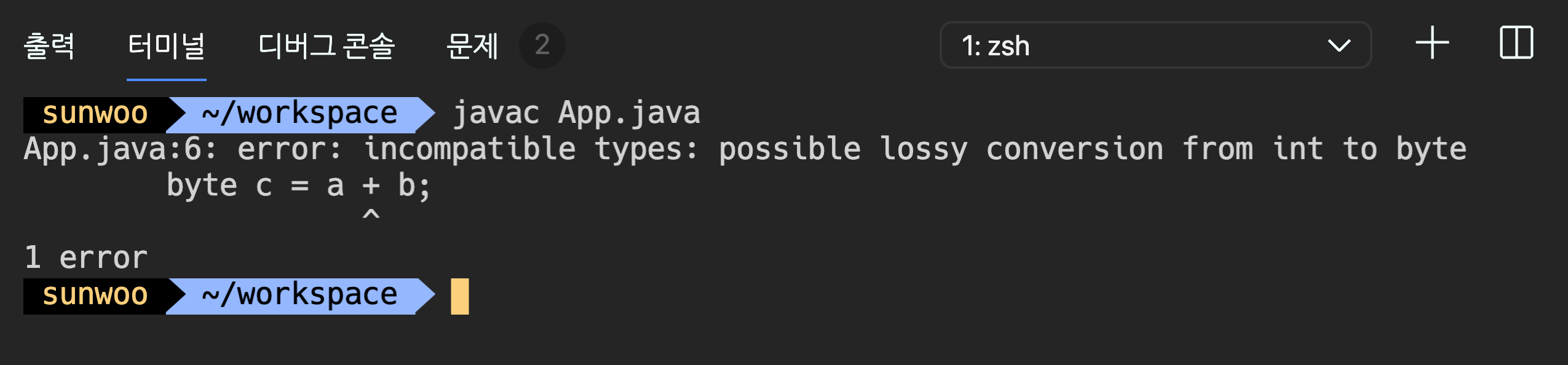
a와 b는 int형 보다 작은 byte형이기 때문에 연산자 +는 두 개의 피연산자들의 자료형을 int 형으로 변환한 다음 연산을 수행한다. 그 결과 ‘a + b’의 연산결과는 4byte의 int 형이 되고 4 byte의 값을 1 byte의 변수에 형변환없이 저장하려고 했기 때문에 에러가 발생한 것이다.
따라서 byte c = (byte)(a + b);와 같이 변환해야 컴파일 에러가 발생하지 않는다.
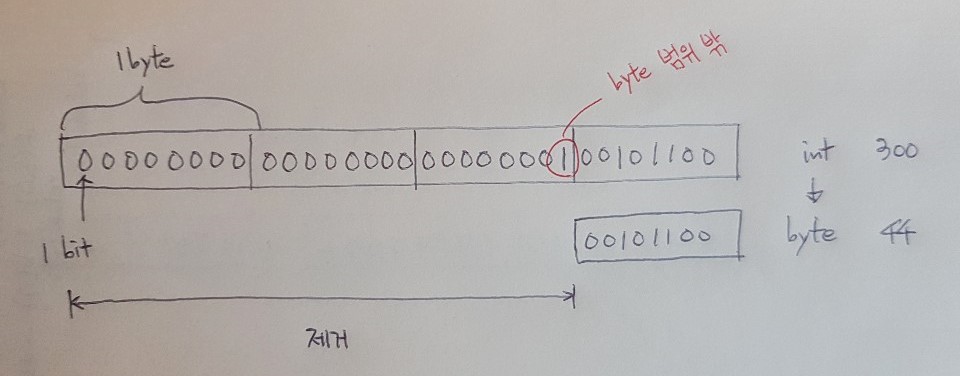
byte형에서 int형으로 변환하는 것은 2진수 8자리에서 32자리로 변환하는 것이기 때문에 데이터 손실이 발생하지 않는다. 기존 8자리는 그대로 보존하고 나머지는 0으로 채우는데 음수인 경우 부호를 유지하기 위해 1로 채운다.
반대로 int형에서 byte형으로 변환하는 경우 앞의 24자리를 없애고 하위 8자리만 보존하는데, 이 때 byte형의 범위인 ‘-128 ~ 127’을 넘는 int형의 값을 변환하면 데이터의 손실이 발생한다. 예를 들어 int의 값이 300이고 이를 byte형으로 변환할 경우 44가 된다.
연산을 할 때 항상 주의해야 하는 것은 피연산자의 타입을 연산 전에 맞춰야 한다.
int a = 1_000_000;
int b = 2_000_000;
long c = a * b;
위 코드를 실행했을 때 변수 c의 자료형이 long 타입이기 때문에 저장공간이 충분하여 ‘2000000000000’이 출력될 것 같지만, 다른 값이 출력된다.
왜냐하면 int타입 간의 연산결과는 int타입이기 때문이다. a * b의 연산결과로 이미 int타입의 값이 연산되었고 long 타입으로 자동 형변환이 되어도 값은 변하지 않는다.
또 한 가지 주의해야 할 점은 같은 의미의 식이라도 연산의 순서에 따라서 다른 결과를 얻을 수 있다.
public class App {
public static void main(String[] args) {
int a = 1_000_000;
int result1 = a * a / a;
int result2 = a / a * a;
System.out.println(a + "*" + a + "/" + a + " = " + result1);
System.out.println(a + "/" + a + "*" + a + " = " + result2);
}
}
일반적인 수식 계산이라면 위의 값은 둘 다 ‘1000000’으로 동일해야 한다. 하지만 실행해보면 결과 값이 다르다
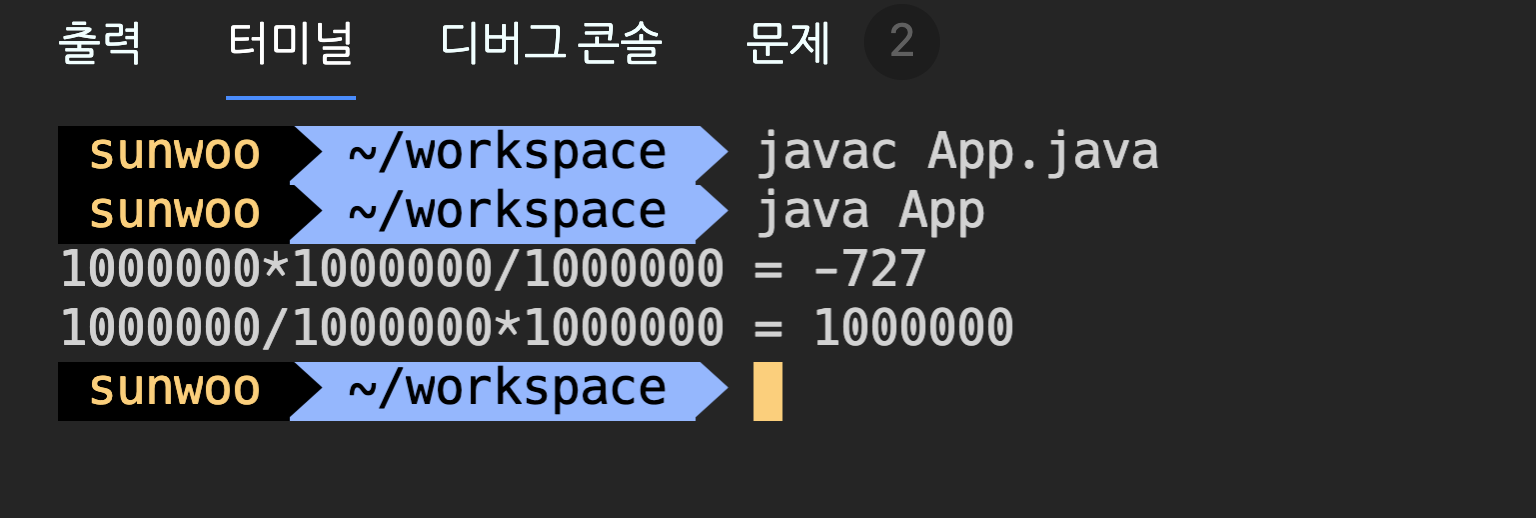
곱셈을 먼저하는 경우 int의 범위를 넘어서서 오버플로우가 발생하기 때문이다.
사칙연산의 피연산자로 숫자뿐만 아니라 문자도 가능하다. 문자는 실제로 해당 문자의 유니코드(부호없는 정수)로 바뀌어 저장되므로 문자간의 사칙연산은 정수간의 연산과 동일하다. 주로 문자간의 뺄셈을 하는 경우가 대부분이며, 문자 ‘2’를 숫자로 변환하려면 다음과 같이 문자 ‘0’을 빼주면 된다.
문자 ‘2’의 유니코드는 50이고, 문자 ‘0’은 48이므로, 두 문자간의 뺄셈은 2를 결과로 얻는다.
아래의 표는 유니코드의 일부로 ‘0’ ~ ‘9’까지의 문자가 연속으로 배치되어 있는 것을 알 수 있다. 그렇기 때문에 해당 문자에서 ‘0’을 빼주면 숫자로 변환되는 것이다.
‘A’ ~ ‘Z’와 ‘a’ ~ ‘z’도 마찬가지로 연속으로 배치되어 있기 때문에 해당 대문자에서 ‘A’, 또는 해당 소문자에서 ‘a’를 빼면 숫자를 얻을 수 있다.
| 문자 | 코드 | 문자 | 코드 | 문자 | 코드 |
| 0 | 48 | A | 65 | a | 97 |
| 1 | 49 | B | 66 | b | 98 |
| 2 | 50 | C | 67 | c | 99 |
| 3 | 51 | D | 68 | d | 100 |
| 4 | 52 | E | 69 | e | 101 |
| 5 | 53 | ... | ... | ... | ... |
| 6 | 54 | W | 87 | w | 119 |
| 7 | 55 | X | 88 | x | 120 |
| 8 | 56 | Y | 89 | y | 121 |
| 9 | 57 | Z | 90 | z | 122 |
대문자와 소문자 간의 코드 값 차이를 보면 32만큼 차이가 나는 것을 알 수 있다. 이 사실을 이용하면 대문자를 소문자로, 소문자를 대문자로 간단하게 변환할 수 있다.
char c1 = 'a';
char c2 = 'a' + 1;
System.out.println(c2);
위 예제를 컴파일 하면 오류가 발생하지 않고 올바른 결과가 얻어진다. 덧셈 연산자와 같은 이항 연산자는 int보다 작은 타입의 피연산자를 int로 자동 형변환한다고 배웠는데, 어째서 char형으로 형변환을 해주지 않고도 문제가 없는 것일까?
그것은 'a' + 1이 리터럴 간의 연산이기 때문이다. 상수 또는 리터럴 간의 연산은 실행과정동안 변하는 값이 아니기 때문에, 컴파일 시에 컴파일러가 계산해서 그 결과로 대체함으로써 코드를 보다 효율적으로 만든다.
만일 a + 1과 같이 수식에 변수가 들어가 있는 경우 컴파일러가 미리 계산할 수 없기 때문에 형변환을 해주어야 한다.
나머지 연산자
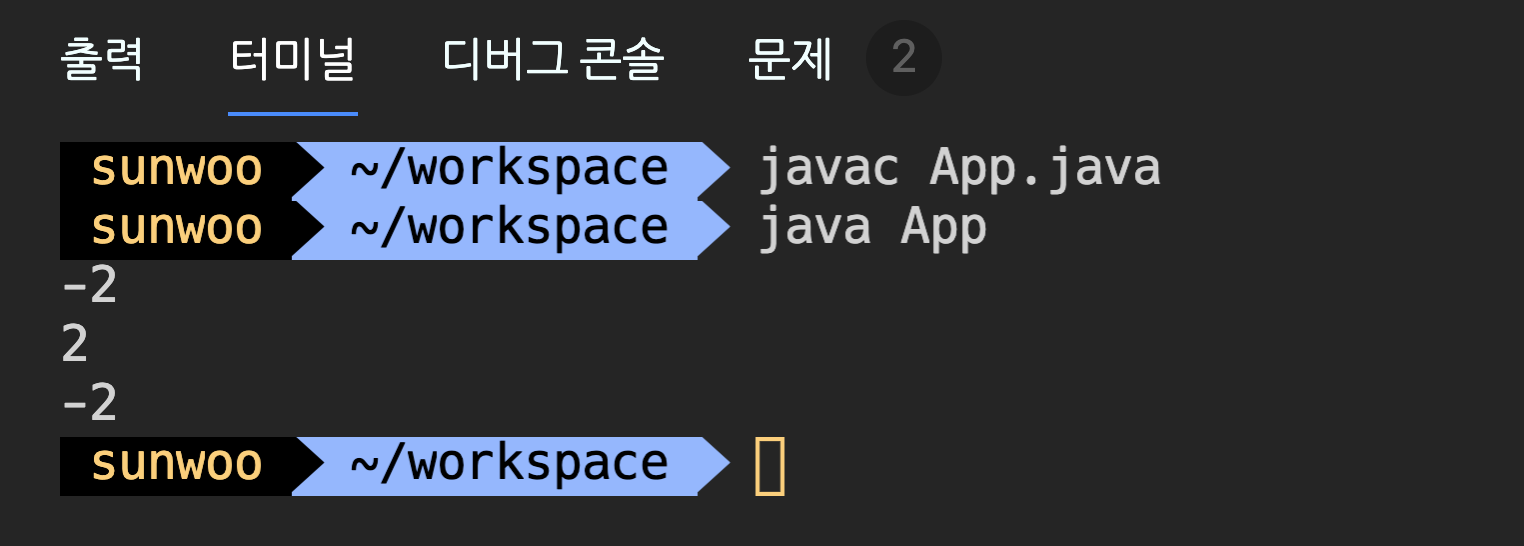
나머지 연산자는 왼쪽의 피연산자를 오른쪽 피연산자로 나누고 난 나머지 값을 결과로 반환하는 연산자이다. 주로 짝수, 홀수 또는 배수 검사 등에 사용된다.
나머지 연산자는 나누는 수로 음수도 허용한다. 그러나 부호는 무시되므로 결과는 음수의 절대값으로 나눈 나머지와 결과가 같다.
그냥 피연산자의 부호를 모두 무시하고, 나머지 연산을 한 결과에 왼쪽 피연산자(나눠지는 수)의 부호를 붙이면 된다.
public class App {
public static void main(String[] args) {
System.out.println(-10 % 8);
System.out.println(10 % 8);
System.out.println(-10 % -8);
}
}
비트 연산자
비트 연산자는 피연산자를 비트단위로 논리 연산한다. 피연산자를 이진수로 표현했을 때의 각 자리를 규칙에 따라 연산을 수행하며, 피연산자로 실수는 허용하지 않는다. 오직 정수(문자 포함)만 허용된다.
규칙은 다음과 같다.
- | (OR 연산자) : 피연산자 중 한 쪽의 값이 1이면, 1을 결과로 얻는다. 그 외에는 0을 얻는다.
- & (AND 연산자) : 피연산자 양 쪽이 모두 1이어야 1을 결과로 얻는다. 그 외에는 0을 얻는다.
- ^ (XOR 연산자) : 피연산자의 값이 서로 다를 때만 1을 결과로 얻는다. 같을 때는 0을 얻는다. 배타적 OR(eXclusive OR)라고도 한다.
비트 연산자의 연산결과를 표로 나타내면 다음과 같다.
| x | y | x | y | x & y | x ^ y |
| 1 | 1 | 1 | 1 | 0 |
| 1 | 0 | 1 | 0 | 1 |
| 0 | 1 | 1 | 0 | 1 |
| 0 | 0 | 0 | 0 | 0 |
비트 전환 연산자 ~
이 연산자는 피연산자를 2진수로 표현했을 때, 0은 1로 1은 0으로 바꾼다. 논리부정 연산자 !와 유사하다.
비트 전환 연산자 ~에 의해 ‘비트 전환’이 되고 나면, 부호있는 타입의 피연산자는 부호가 반대로 변경된다. 즉, 피연산자의 ‘1의 보수’를 얻을 수 있는 것이다. 그래서 비트 전환 연산자를 1의 보수 연산자라고도 한다.
비트 전환 연산자는 피연산자의 타입이 int보다 작으면 int로 자동 형변환(산술 변환) 후에 연산하기 때문에 연산결과는 32자리의 2진수이다.
public class App {
public static void main(String[] args) {
byte p = 10;
byte n = -10;
System.out.printf("p = %d \t\t%s%n", p, toBinaryString(p));
System.out.printf("~p = %d \t%s%n", ~p, toBinaryString(~p));
System.out.printf("~p + 1 = %d \t%s%n", ~p + 1, toBinaryString(~p + 1));
System.out.printf("~~p = %d \t%s%n", ~~p, toBinaryString(~~p));
}
static String toBinaryString(int x) {
String zero = "00000000000000000000000000000000";
String tmp = zero + Integer.toBinaryString(x);
return tmp.substring(tmp.length() - 32);
}
}
![]()
~~p는 변수 p에 비트 전환 연산을 두 번 적용한 것인데 원래의 값이 출력되지만 타입은 int형이다.
쉬프트 연산자 « »
쉬프트 연산자는 피연산자의 각 자리(2진수로 표현했을 때)를 오른쪽(») 또는 왼쪽(«)으로 이동(shift)한다고 해서 쉬프트 연산자(shift operator)라고 이름이 붙었다.
예를 들어 8 << 2는 왼쪽 피연산자인 10진수 8의 2진수를 왼쪽으로 2자리 이동한다. 이 때, 자리이동으로 저장범위를 벗어난 값들은 버려지고 빈자리는 0으로 채워진다.
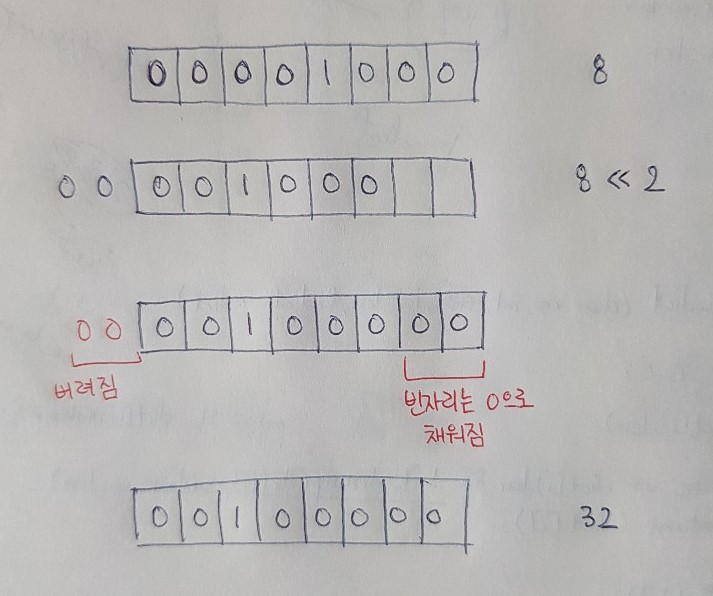
<< 연산자의 경우, 피연산자의 부호에 상관없이 각 자리를 왼쪽으로 이동시키며 빈칸을 0으로 채우면 되지만, >> 연산자는 오른쪽으로 이동시키기 때문에 부호있는 정수는 부호를 유지하기 위해 왼쪽 피연산자가 양수인 경우에는 0으로, 음수인 경우 빈자리를 1로 채운다.
쉬프트 연산자의 좌측 피연산자는 산술변환이 적용되어 int보다 작은 타입은 int타입으로 자동 변환되고 연산결과 역시 int타입이 된다. 그러나 피연산자의 타입을 일치시킬 필요가 없기 때문에 우측 피연산자에는 산술변환이 적용되지 않는다.
2진수 n자리를 왼쪽으로 이동하면 피연산자를 2n으로 곱한 결과를, 오른쪽으로 이동하면 피연산자를 2n으로 나눈 결과를 얻는다.
|
x << n은 x * 2n의 결과와 같다. x >> n은 x / 2n의 결과와 같다. |
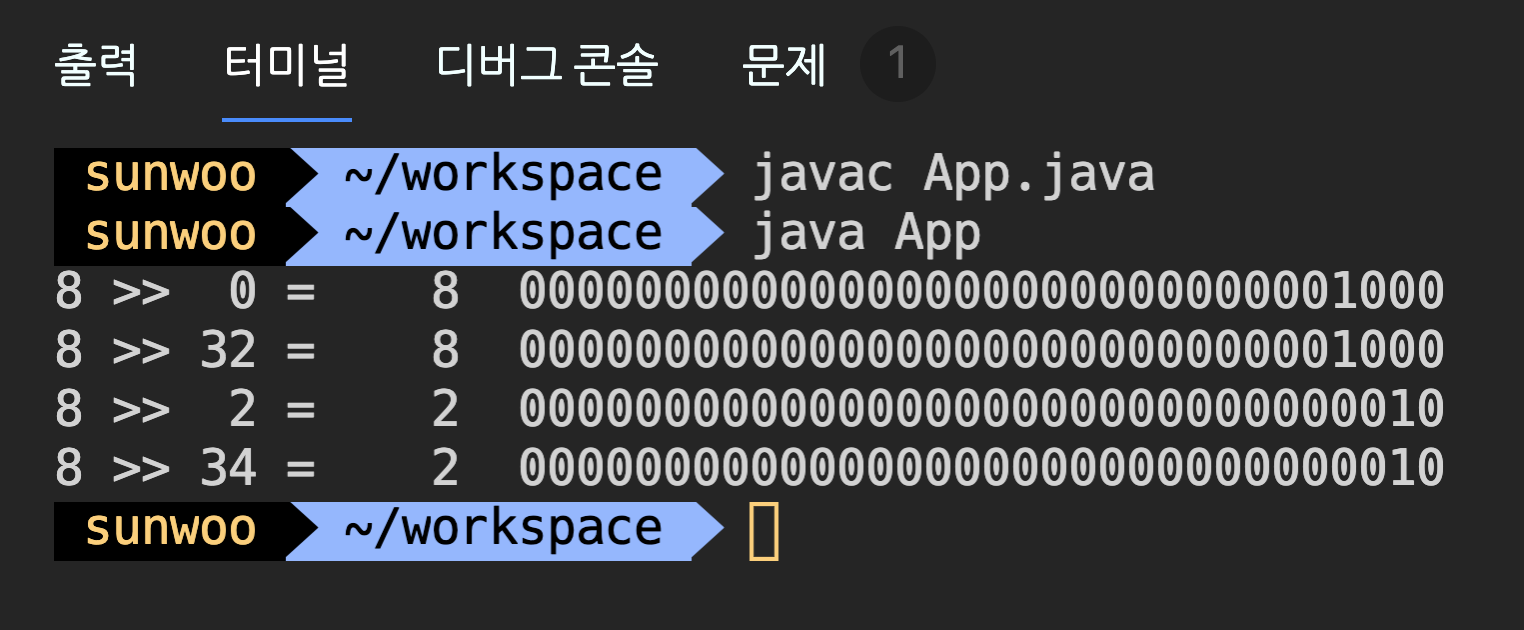
x << n 또는 x >> n에서 n의 값이 자료형의 bit수 보다 크면, 자료형의 bit수로 나눈 나머지만큼만 이동한다. 예를 들어 int타입은 4 byte(=32bit)인데, 자리수를 32번 바꾸면 결국 제자리로 돌아오게 된다. 8 >> 32는 아무 일도 하지 않는다. 만일 34라면 34를 32로 나눈 나머지인 2만큼만 이동하는 8 >> 2를 수행한다.
public class App {
public static void main(String[] args) {
int dec = 8;
System.out.printf("%d >> %2d = %4d \t%s%n", dec, 0, dec >> 0, toBinaryString(dec >> 0));
System.out.printf("%d >> %2d = %4d \t%s%n", dec, 32, dec >> 32, toBinaryString(dec >> 32));
System.out.printf("%d >> %2d = %4d \t%s%n", dec, 2, dec >> 2, toBinaryString(dec >> 2));
System.out.printf("%d >> %2d = %4d \t%s%n", dec, 34, dec >> 34, toBinaryString(dec >> 34));
}
static String toBinaryString(int x) {
String zero = "00000000000000000000000000000000";
String tmp = zero + Integer.toBinaryString(x);
return tmp.substring(tmp.length() - 32);
}
}
관계 연산자
관계 연산자(Relational Operator) 또는 비교 연산자(Comparing Operator)라 불리는 연산자는 두 피연산자를 비교하는 데 사용되는 연산자이다. 주로 조건문과 반복문의 조건식에 사용되며, 연산결과는 오직 true와 false 둘 중의 하나이다.
대소비교 연산자 < > <= >=
두 피연산자의 값의 크기를 비교하는 연산자로 참이면 true를, 거짓이면 false를 반환한다. 기본형 중에서 boolean형을 제외한 나머지 자료형에 다 사용할 수 있지만 참조형에는 사용할 수 없다.
| 관계 연산자 | 연산결과 |
| > | 좌변 값이 크면 true, 아니면 false |
| < | 좌변 값이 작으면 true, 아니면 false |
| >= | 좌변 값이 크거나 같으면 true, 아니면 false |
| <= | 좌변 값이 작거나 같으면 true, 아니면 false |
>=와 같이 두 개의 기호로 이루어진 연산자는 =>처럼 기호의 순서를 바꾸거나 > =와 같이 중간에 공백이 들어가서는 안된다.
등가비교 연산자 == !=
두 피연산자의 값이 같은지 또는 다른지를 비교하는 연산자이다. 대소비교 연산자와 달리 기본형은 물론 참조형, 즉 모든 자료형에 사용할 수 있다.
기본형의 경우 변수에 저장되어 있는 값이 같은지를 알 수 있고, 참조형의 경우 객체의 주소값을 저장하기 때문에 두 개의 피연산자(참조변수)가 같은 객체를 가리키고 있는지를 알 수 있다.
기본형과 참조형은 서로 형변환이 가능하지 않기 때문에 등가비교 연산자(==, !=)로 서로 비교할 수 없다.
| 비교 연산자 | 연산결과 |
| == | 두 값이 같으면 true, 아니면 false |
| != | 두 값이 다르면 true, 아니면 false |
public class App {
public static void main(String[] args) {
System.out.printf("10 == 10.0f \t %b%n", 10 == 10.0f);
System.out.printf("'0' == 0 \t %b%n", '0' == 0);
System.out.printf("'A' == 65 \t %b%n", 'A' == 65);
System.out.printf("'A' > 'B' \t %b%n", 'A' > 'B');
System.out.printf("'A' + 1 != 'B' \t %b%n", 'A' + 1 != 'B');
}
}
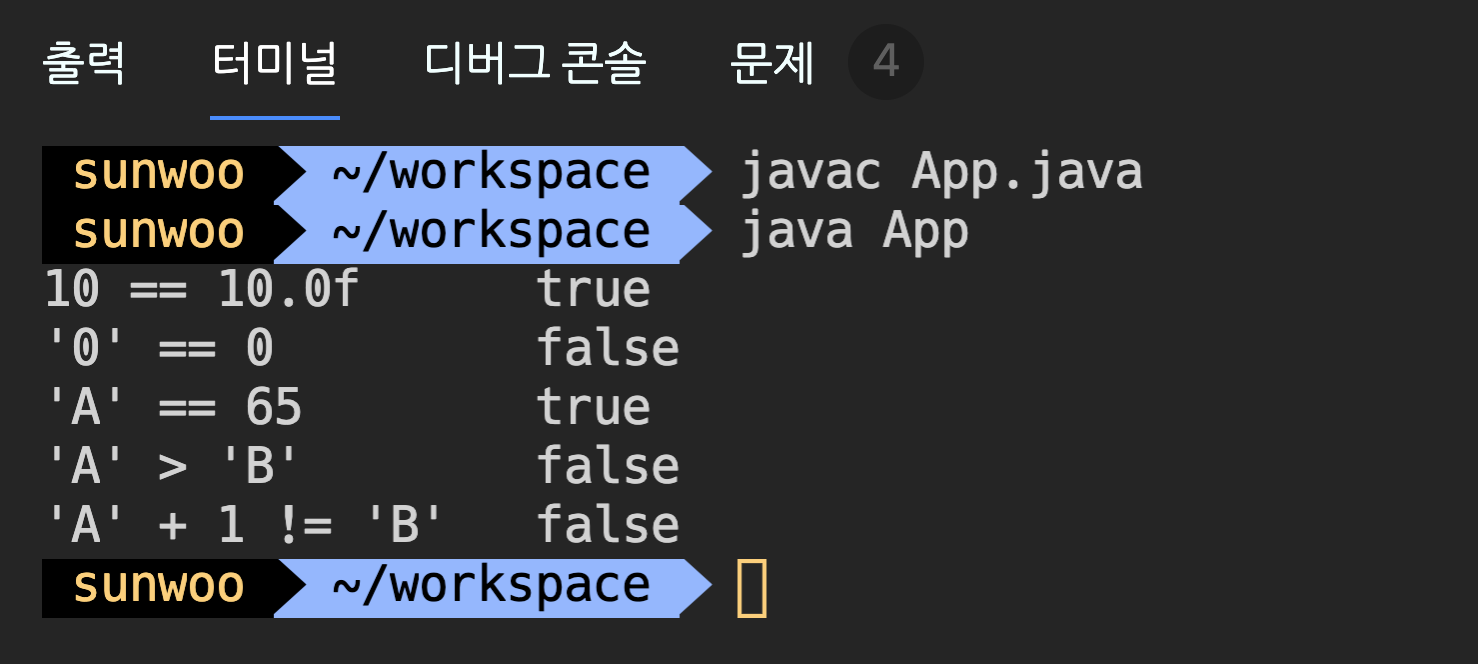
비교 연산자도 이항 연산자이므로 연산을 수행하기 전에 형변환을 통해 두 피연산자의 타입을 같게 맞춘 다음 피연산자를 비교한다.
문자열의 비교
두 문자열을 비교할 때는, 비교 연산자 ‘==’ 대신 equals()라는 메서드를 사용해야 한다. 비교 연산자는 두 문자열이 완전히 같은 것인지 비교할 뿐이고, 문자열의 내용이 같은지 비교하기 위해서는 equals()를 사용해야한다. equals()는 비교하는 두 문자열이 같으면 true, 다르면 false를 반환한다.
public class App {
public static void main(String[] args) {
String str1 = "abc";
String str2 = new String("abc");
System.out.printf("\"abc\" == \"abc\" ? %b%n", "abc" == "abc");
System.out.printf(" str1 == \"abc\" ? %b%n", str1 == "abc");
System.out.printf(" str2 == \"abc\" ? %b%n", str2 == "abc");
System.out.printf("str1.equals(\"abc\") ? %b%n", str1.equals("abc"));
System.out.printf("str1.equals(\"abc\") ? %b%n", str2.equals("abc"));
}
}
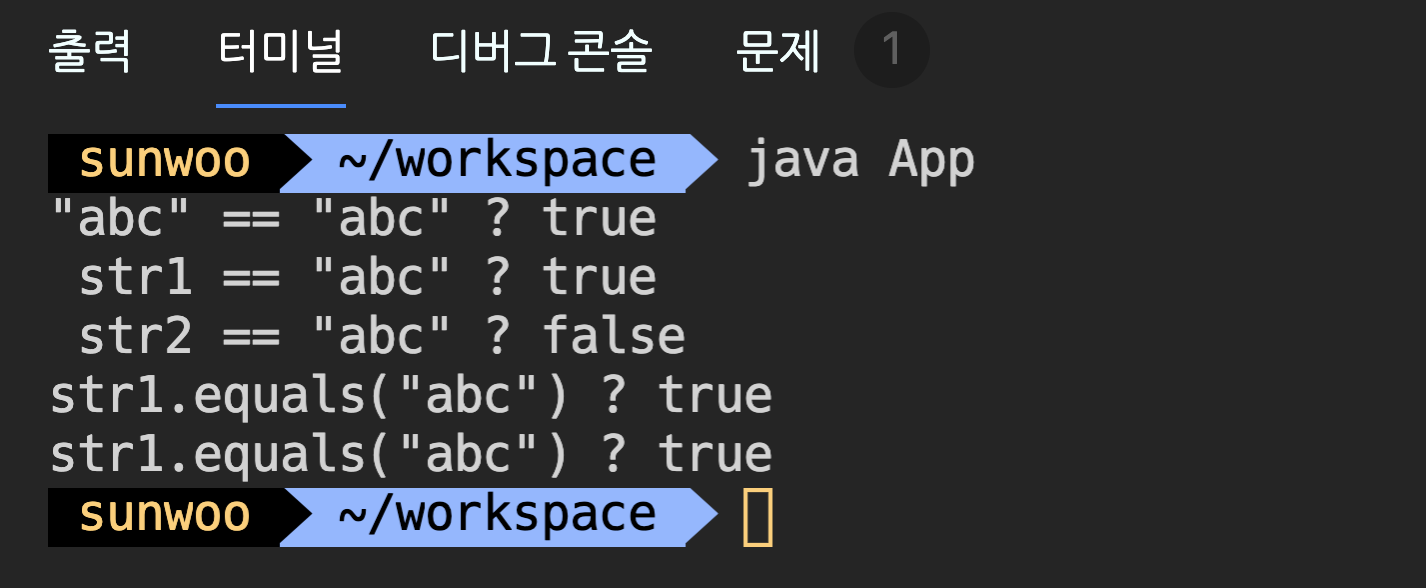
str2와 “abc”는 내용이 같은데 ‘==’로 비교하면 false를 얻는다. 왜냐하면 내용은 같지만 서로 다른 객체이기 떄문이다. equals()는 객체가 달라도 내용이 같으면 true를 반환하기 대문에 문자열을 비교할 때는 equals()를 사용해야 한다.
논리 연산자
‘x는 4보다 작다.’, ‘x는 10보다 크다’와 같이 한 가지의 조건에 대한 비교는 비교연산자를 써서 표현할 수 있다. 그렇다면 ‘x는 4보다 작고 10보다 크다’와 같이 두 개의 조건이 결합된 경우에는 어떻게 해야 할까? 이 때 사용하는 것이 논리 연산자이다.
논리 연산자는 둘 이상의 조건을 ‘그리고(AND)’나 ‘또는(OR)’으로 연결하여 하나의 식으로 표현할 수 있게 한다.
논리 연산자 - &&, ||, !
논리 연산자 &&는 ‘그리고(AND)’에 해당하며, 두 연산자가 모두 true일 때만 true를 결과로 얻는다.
||는 ‘또는(OR)’에 해당하며, 두 피연산자 중 어느 한 쪽만 true이어도 true를 결과로 얻는다.
논리 연산자는 피연산자로 ‘boolean형’ 또는 ‘boolean형 값을 결과로 하는 조건식’만을 허용한다.
| x | y | x || y | x && y |
| true | true | true | true |
| true | false | true | false |
| false | true | true | false |
| false | false | false | false |
&&는 문장에 ‘그리고(AND)’로 연결된 조건에 사용되는데, 예를 들어 ‘x는 10보다 크고, 20보다 작다’라는 문장의 경우 x > 10 && x < 20으로 표현할 수 있다.
보통 변수는 왼쪽에 쓰이지만 가독성측면에서 10 < x && x < 20으로 쓸 수도 있다. 하지만 이 때 논리연산자를 생략하고 10 < x < 20과 같이 표현하는 것은 허용되지 않는다.
논리 부정 연산자 !
이 연산자는 피연산자가 true이면 false를, false이면 true를 결과로 반환하며, 주로 조건문과 반복문의 조건식에 사용된다.
어떠한 값에 논리 부정 연산자 !를 반복적으로 적용하면, 참과 거짓이 차례대로 반복된다. 이러한 성질을 이용해서 ‘토클 버튼(toggle button)’을 구현할 수 있다.
효율적인 연산(short circuit evaluation)
논리 연산자의 특징 중 하나는 효율적인 연산을 한다는 것이다.
OR 연산자 ||은 둘 중 하나만 true이어도 전체 연산결과가 true이므로 좌측 피연산자가 true이면, 우측 피연산자의 값은 평가하지 않는다.
AND 연산자 &&는 어느 한 쪽만 false여도 전체 연산결과가 false이므로 좌측 피연산자가 false이면, 우측 피연산자의 값은 평가하지 않는다.
따라서 같은 조건식이어도 피연산자의 위치에 따라서 연산속도가 달라질 수도 있다.
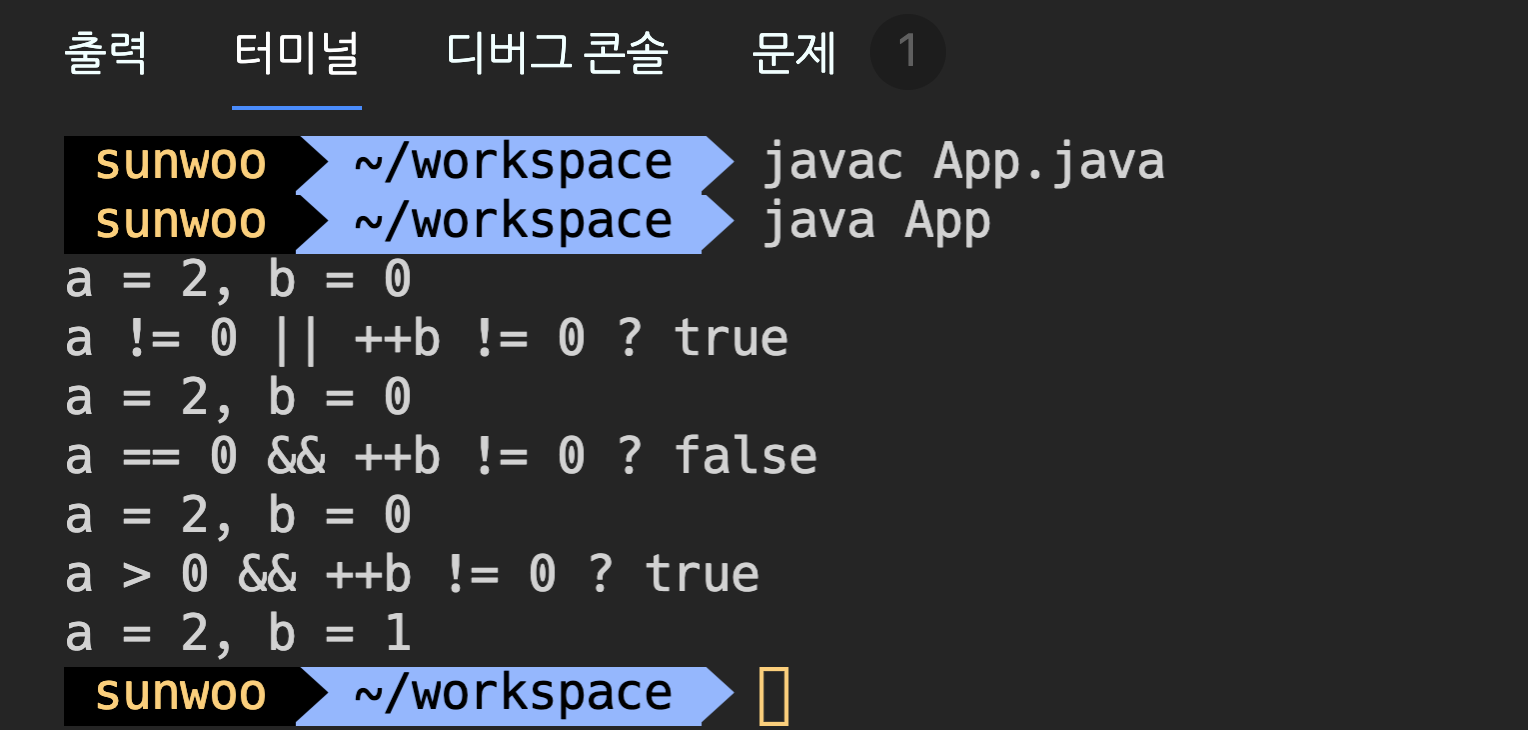
다음 코드는 우측 피연산자가 처리되는지를 확인하기 위한 코드이다.
public class App {
public static void main(String[] args) {
int a = 2;
int b = 0;
System.out.printf("a = %d, b = %d %n", a, b);
System.out.printf("a != 0 || ++b != 0 ? %b%n", a != 0 || ++b != 0);
System.out.printf("a = %d, b = %d %n", a, b);
System.out.printf("a == 0 && ++b != 0 ? %b%n", a == 0 && ++b != 0);
System.out.printf("a = %d, b = %d %n", a, b);
System.out.printf("a > 0 && ++b != 0 ? %b%n", a > 0 && ++b != 0);
System.out.printf("a = %d, b = %d %n", a, b);
}
}
instanceof
instanceof연산자는 참조변수가 참조하고 있는 인스턴스의 실제 타입을 알아보기 위해 사용한다. 주로 조건문에 사용되며 좌측에는 참조변수가, 우측에는 타입(클래스명)이 피연산자로 위치한다. 연산 결과로 boolean값인 true와 false 중의 하나를 반환한다. 값이 null인 참조변수에 대해 수행할 경우 false를 결과로 얻는다.
instanceof를 이용한 연산결과로 true를 얻었다는 것은 참조변수가 검사한 타입으로 형변환이 가능하다는 것을 뜻한다.
조상타입의 참조변수로 자손타입의 인스턴스를 참조할 수 있기 때문에, 참조변수의 타입과 인스턴스의 타입이 항상 일치하지는 않는다. 조상타입의 참조변수로는 실제 인스턴스의 멤버들을 모두 사용할 수 없기 때문에, 실제 인스턴스와 같은 타입의 참조변수로 형변환을 해야만 인스턴스의 모든 멤버들을 사용할 수 있다.
public class App {
public static void main(String[] args) {
Student me = new Student();
if (me instanceof Student) {
System.out.println("This is a Student instance.");
}
if (me instanceof JavaStudy) {
System.out.println("This is a JavaStudy instance.");
}
if (me instanceof Object) {
System.out.println("This is a an Object instance.");
}
System.out.println(Me.getClass().getName());
}
}
class JavaStudy {
}
class Student extends JavaStudy {
}
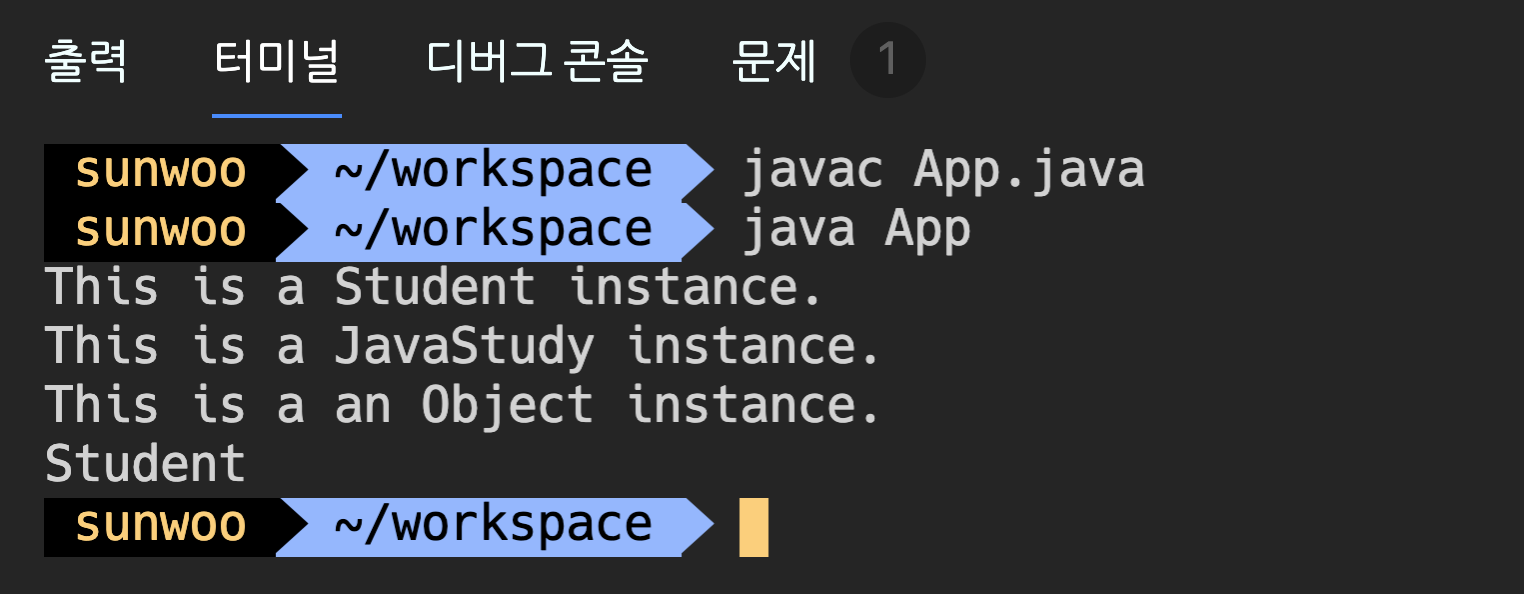
me라는 인스턴스는 Student타입인데도, Object타입과 JavaStudy타입의 instanceof연산에서도 true를 얻었다.
이유는 Student클래스는 Object클래스와 JavaStudy클래스의 자손 클래스이므로 조상의 멤버들을 상속받았기 때문에, Student인스턴스는 Object인스턴스와 JavaStudy인스턴스를 포함하고 있다고 볼 수 있다.
assignment(=) operator
대입 연산자(assignment operator)는 변수와 같은 저장공간에 값 또는 수식의 연산결과를 저장하는데 사용된다. 이 연산자는 오른쪽 피연산자의 값(식이라면 평가값)을 왼쪽 피연산자에 저장한다. 그리고 저장된 값을 연산결과로 반환한다.
대입 연산자는 연산자들 중에서 가장 낮은 우선순위를 가지고 있기 때문에 식에서 가장 마지막에 수행된다. 또한 연산 진행 방향이 오른쪽에서 왼쪽이기 때문에 x = y = 3;을 시행하면 y = 3이 먼저 수행되고 x = y가 수행된다.
lvalue와 rvalue
대입 연산자의 왼쪽 피연산자를 ‘lvalue(left value)’라 하고, 오른쪽 피연산자를 ‘rvalue(right value)’라고 한다.
대입 연산자의 rvalue는 변수 뿐만 아니라 식이나 상수 등이 모두 가능한 반면에 lvalue는 반드시 변수처럼 값을 변경할 수 있는 것이어야 한다.
int i = 0;
1 = i + 1; // 에러. lvalue가 값을 저장할 수 있는 공간이 아니다.
i + 1 = i; // 에러. lvalue의 연산결과가 리터럴이다.(i + 1 -> 0 + 1 -> 1)
final int MAX = 1;
MAX = 10; // 에러. 상수(MAX)에 새로운 값을 저장할 수 없다.
변수 앞에 키워드 final을 붙이면 상수가 된다. 상수는 반드시 선언과 동시에 값을 저장해야하며, 한 번 저장된 값은 바꿀 수 없다.
복합 대입 연산자
대입 연산자는 다른 연산자(op)와 결합하여 op=와 같은 방식으로 사용될 수 있다. 결합된 두 연산자는 반드시 공백없이 붙여 써야 한다.
| op= | = |
| i += 1; | i = i + 1; |
| i -= 1; | i = i - 1; |
| i *= 1; | i = i * 1; |
| i /= 1; | i = i / 1; |
| i %= 1; | i = i % 1; |
| i <<= 1; | i = i << 1; |
| i >>= 1; | i = i >> 1; |
| i &= 1; | i = i & 1; |
| i ^= 1; | i = i ^ 1; |
| i |= 1; | i = i | 1; |
| i *= 10 + j; | i = i * (10 + j); |
표에서 마지막 식은 대입 연산자의 우변이 둘 이상의 항으로 이루어져 있는 경우이다. i = i * 10 + j로 착각하지 않도록 주의해야 한다.
화살표(->) 연산자
JDK 1.8부터 자바에 추가된 람다식(Lambda expression)의 도입으로 인해 자바는 객체지향언어인 동시에 함수형 언어가 되었다.
람다식이란?
람다식(Lambda expression)은 메서드를 하나의 ‘식(expression)’으로 표현한 것이다. 함수를 간략하면서도 명확한 식으로 표현할 수 있게 해준다.
메서드를 람다식으로 표현하면 메서드의 이름과 반환 값이 없어지므로, 람다식을 ‘익명 함수(anonymous function)’라고도 한다.
int[] arr = new int[5];
Arrays.setAll(arr, (i) -> (int)(Math.random() * 5) + 1);
위 코드에서 () -> (int)(Math.random() * 5) + 1이 람다식이다. 이 람다식을 메서드로 표현하면 다음과 같다.
int method() {
return (int)(Math.random() * 5) + 1;
}
모든 메서드는 클래스에 포함되어야 하므로 클래스를 생성하고, 객체도 생성해야만 메서드를 호출할 수 있다. 그러나 람다식은 이 모든 과정없이 람다식 자체만으로도 메서드의 역할을 대신할 수 있다.
람다식은 메서드의 매개변수로 전달되어지는 것이 가능하고, 메서드의 결과로 반환될 수도 있다. 람다식으로 인해 메서드를 변수처럼 다루는 것이 가능해진 것이다.
람다식 작성
람다식은 ‘익명 함수’답게 메서드에서 이름과 반환타입을 제거하고 매개변수 선언부와 몸통 { } 사이에 ->를 추가한다.
반환타입 메서드이름(매개변수 선언) {
문장
}
위와 같은 형태에서 아래와 같이 바뀌는 것이다.
(매개변수 선언) -> { 문장 }
예를 들어 두 값 중에서 큰 값을 반환하는 메서드 max가 있다.
int max(int a, int b) {
return a > b ? a : b;
}
이 것을 람다식으로 변환하면 다음과 같이 된다.
(int a, int b) -> {
return a > b ? a : b;
}
반환값이 있는 메서드의 경우, return문 대신 ‘식(expression)’으로 대신 할 수 있다. 식의 연산결과가 자동적으로 반환값이 되는데 이 때 ‘문장(statement)’이 아닌 ‘식’이므로 끝에 ;를 붙이지 않는다.
(int a, int b) -> a > b ? a : b
람다식에 선언된 매개변수의 타입은 추론이 가능한 경우 생략할 수 있는데, 두 매개변수 중 어느 하나의 타입만 생략하는 것은 허용되지 않는다. 대부분의 경우 생략이 가능하고 람다식에 반환타입이 없는 이유는 항상 추론이 가능하기 때문이다.
(a, b) -> a > b ? a : b
선언된 매개변수가 하나뿐인 경우에는 괄호 ( )를 생략할 수 있다. 하지만 매개변수의 타입이 있으면 생략할 수 없다.
a -> a * a // OK.
int a -> a * a // 에러.
또한 괄호 { }안의 문장이 하나인 경우 괄호 { }를 생략할 수 있다. 이 때 문장의 끝에 ;을 붙이지 않아야 한다. 그러나 괄호 { } 안의 문장이 return문일 경우 생략할 수 없다.
(String number, int i) -> {
System.out.println(number + ":" + i);
}
// 괄호 { } 생략
(String number, int i) -> System.out.println(number + ":" + i) // OK.
int roll() {
return (int)(Math.random() * 2);
}
// 괄호 { } 생략
() -> return (int)(Math.random() * 2) // 에러. return문이기 때문에 생략 불가.
3항 연산자
조건 연산자 ? :는 조건식, 식1, 식2 총 세 개의 피연산자를 필요로 하는 3항 연산자이며, 조건 연산자가 유일한 3항 연산자이다.
조건 연산자는 첫 번째 피연산자인 조건식의 평가결과에 따라 다른 결과를 반환한다. 조건식의 평가결과가 true이면 식1이, false이면 식2가 결과로 반환된다. 조건식을 괄호 ( )로 감싸 가독성을 높이기도 하지만 필수는 아니다.
result = (x > y) ? x : y; // x > y가 true이면 x, false이면 y가 변수 result에 저장된다.
조건 연산자는 조건문인 if문으로 바꿔 쓸 수 있으며, if문 대신 조건 연산자를 사용해 코드를 간단히 할 수 있다. 위 조건식을 if문으로 바꾸면 아래와 같다.
if(x > y)
result = x; // true일 때
else
result = y; // false일 때
조건 연산자를 중첩해서 사용하면 셋 이상 중의 하나를 결과로 얻을 수도 있다. 여러 번 중첩하면 코드가 간략해지지만 가독성이 떨어지므로 꼭 필요한 경우에 사용하는 것이 좋다.
조건 연산자의 식1과 식2, 두 피연산자의 타입이 다른 경우 이항 연산자처럼 산술 변환이 발생한다.
연산자 우선 순위
식에 사용된 연산자가 둘 이상인 경우, 연산자의 우선순위에 의해서 연산순서가 결정된다. 수학에서 배웠듯이 곱셈과 나눗셈(*, /)이 덧셈과 뺄셈(+, -)보다 우선순위가 높다는 것을 알고 있다. 연산자의 우선순위는 대부분 상식적인 선에서 해결된다.
다음 표는 우선순위가 높은 순서에서 낮은 순서로 정리된 표이다.
| 종류 | 연산자 | 우선순위 |
| 단항 연산자 | ++, --, +, -, ~, ! | 높음 낮음 |
| 산술 연산자 | *, /, % | |
| +, - | ||
| <<, >> | ||
| 비교 연산자 | <, >, <=, >=, instanceof | |
| ==, != | ||
| 논리 연산자 | & | |
| ^ | ||
| | | ||
| && | ||
| || | ||
| 삼항 연산자 | ? : | |
| 대입 연산자 | =, +=, -=, *=, /=, %=, <<=, >>=, &=, ^=, |= |
연산자의 결합규칙
하나의 식에 같은 우선순위의 연산자들이 여러 개 있는 경우, 우선순위가 같다고 아무거나 먼저 처리되는 것이 아니다. 나름의 규칙을 가지고 있는데 그 규칙을 연산자의 결합규칙이라고 한다.
결합규칙은 연산자마다 다르지만, 대부분 왼쪽에서 오른쪽의 순서로 연산을 수행하고, 단항 연산자와 대입 연산자만 반대인 오른쪽에서 왼쪽으로 수행한다.
예를 들어 2 + 3 - 4는 덧셈연산자의 결합방향이 왼쪽에서 오른쪽이므로 수식의 왼쪽에 있는 2 + 3을 먼저 계산하고, 그 결과인 5와 4의 뺄셈을 수행한다.
반대로 x = y = 2에서 대입 연산자는 결합규칙이 오른쪽에서 왼쪽이므로 오른쪽의 대입 연산자가 먼저 수행된다. y = 2가 먼저 수행되어서 y에 2가 저장되고 그 다음에 x = 2가 수행되어 x에 2가 저장된다.
정리
-
산술 > 비교 > 논리 > 대입. 대입이 가장 마지막에 수행된다.
-
단항(1) > 이항(2) > 삼항(3). 단항 연산자의 우선순위가 이항 연산자보다 높다.
-
단항 연산자와 대입 연산자를 제외한 모든 연산의 진행방향은 왼쪽에서 오른쪽이다.
Java 13. switch 연산자
Java 12
Java 12에서 Switch문이 확장되었다.
기존의 Switch문의 작성법은 아래와 같았다.
String time;
switch(weekday) {
case MONDAY:
case FRIDAY:
time = "10:00 - 18:00";
break;
case TUESDAY:
case THURSDAY:
time = "10:00 - 14:00";
break;
default:
time = "휴일";
}
Switch문을 사용하게 되면 작성해야 하는 양이 많았지만 break나 값 설정 부분이 간략하게 되었다.
복수의 case
case에 복수의 값을 설정할 수 있게 되었다.
switch(weekday) {
case MONDAY, FRIDAY:
time = "10:00 - 18:00";
break;
case TUESDAY, THURSDAY:
time = "10:00 - 14:00";
break;
default:
time = "휴일";
}
지시자(->) 문법
지시자(->)를 사용하여 break를 생략할 수 있게 되었다.
String time;
switch(weekday) {
case MONDAY, FRIDAY -> time = "10:00 - 18:00";
case TUESDAY, THURSDAY -> time = "10:00 - 14:00";
default -> time = "휴일";
}
블록을 사용하여 여러가지 처리를 작성할 수 있게 되었다.
String time;
switch(weekday) {
case MONDAY, FRIDAY -> {
var endTime = getEndTime();
time = "10:00 - " + endTime;
}
case TUESDAY, THURSDAY -> time = "10:00 - 14:00";
default -> time = "휴일";
}
Switch 식
Switch를 식으로도 사용할 수 있다. 지시자 문법을 사용하지 않는 경우나 지시자 문법에 블록을 사용한 경우 break로 값을 반환한다.
String time = switch(weekday) {
case MONDAY, FRIDAY -> {
var endTime = getEndTime();
break "10:00 - " + endTime;
}
case TUESDAY, THURSDAY -> "10:00 - 14:00";
default -> "휴일";
};
Java 13
Java 13에서 수정사항이 생겼는데, break로 값을 반환하는 문법이 yield로 변경되었다.
<Java12>
String result = switch(code) {
case 1:
break "code 1";
case 2:
break "code 2";
default:
break "default";
};
System.out.println(result);
<Java13>
String result = switch(code) {
case 1:
yield "code 1";
case 2:
yield "code 2";
default:
yield "default";
};
System.out.println(result);
break를 이용한 값 반환 방법이 없어지고 대안으로 yield를 사용할 수 있게 된 것이다.
Reference
Comments
JAVA STUDY HALLE 의 다른 글
-
15주차 피드백 06 Mar 2021
-
15주차 과제: 람다식. 28 Feb 2021
-
14주차 피드백 27 Feb 2021
-
14주차 과제: 제네릭. 22 Feb 2021
-
13주차 피드백 20 Feb 2021
-
13주차 과제: I/O. 08 Feb 2021
-
12주차 피드백 06 Feb 2021
-
12주차 과제: 애노테이션. 01 Feb 2021
-
11주차 피드백 30 Jan 2021
-
11주차 과제: Enum. 24 Jan 2021
-
10주차 피드백 23 Jan 2021
-
10주차 과제: 멀티쓰레드 프로그래밍. 18 Jan 2021
-
9주차 피드백 16 Jan 2021
-
9주차 과제: 예외 처리. 10 Jan 2021
-
8주차 피드백 09 Jan 2021
-
8주차 과제: 인터페이스. 03 Jan 2021
-
7주차 피드백 02 Jan 2021
-
7주차 과제: 패키지. 28 Dec 2020
-
6주차 피드백 27 Dec 2020
-
6주차 과제: 상속. 21 Dec 2020
-
5주차 피드백 20 Dec 2020
-
5주차 과제: 클래스. 14 Dec 2020
-
4주차 피드백 13 Dec 2020
-
4주차 과제: 제어문. 30 Nov 2020
-
3주차 피드백 29 Nov 2020
-
3주차 과제: 연산자. 22 Nov 2020
-
2주차 피드백 21 Nov 2020
-
2주차 과제: 자바 데이터 타입, 변수 그리고 배열. 15 Nov 2020
-
1주차 피드백 15 Nov 2020
-
1주차 과제: JVM은 무엇이며 자바 코드는 어떻게 실행하는 것인가. 08 Nov 2020