
on
5주차 과제: 클래스.
해당 글을 백기선 님의 자바 스터디 5주차 과제를 공부하고 공유하기 위해서 작성되었습니다.
목표
자바의 Class에 대해 학습한다.
학습할 것
클래스 정의하는 방법
클래스란?
클래스를 정의하기 전에 클래스가 무엇인지 알아보자. 클래스란 ‘객체를 정의해 놓은 것’ 또는 ‘객체의 설계도(틀)’이라고 볼 수 있다. 클래스는 객체를 생성하는데 사용되며, 객체는 클래스에 정의된 대로 생성된다.
- 클래스의 정의 : 객체를 정의해 놓은 것
- 클래스의 용도 : 객체를 생성하는데 사용됨
클래스와 객체의 관계는 제품 설계도와 제품과의 관계라고 할 수 있다. 예를 들어 자동차설계도(클래스)는 자동차라는 제품(객체)을 정의한 것이고, 자동차(객체)를 만드는데 사용된다.
클래스는 단지 객체를 생성하는데 사용될 뿐, 객체 그 자체는 아니다. 설계도가 있다고해서 그 제품을 가진 것은 아니다. 자동차를 사용하기 위해서는 자동차(객체)가 필요하지 자동차설계도(클래스)가 필요한 것은 아니며, 설계도(클래스)는 단지 제품(객체)를 만드는데만 사용된다. 따라서 우리가 원하는 기능의 객체를 사용하기 위해서는 클래스로부터 객체를 생성하는 과정이 선행되어야 한다. 클래스를 정의하고 클래스를 통해 객체를 생성하는 이유는 잘 만든 설계도가 있으면 제품을 만들기 쉬운 것과 마찬가지이다. 클래스를 한번만 잘 만들어 놓으면 객체를 생성할 때마다 매번 고민할 필요없이 클래스로부터 객체를 생성해서 사용하기만 하면 되기 때문이다.
JDK에서는 많은 수의 유용한 클래스(Java API)를 제공하고 있고 이를 이용해서 원하는 기능의 프로그램을 보다 쉽게 작성할 수 있다.
프로그래밍적 관점에서는 데이터와 함수의 결합!
위에서의 클래스는 객체지향이론의 관점에서 내린 정의이고, 프로그래밍적 관점에서는 또 다르다. 프로그래밍언어에서 데이터 처리를 위한 데이터 저장형태의 발전과정은 다음과 같다.

- 변수 : 하나의 데이터를 저장할 수 있는 공간
- 배열 : 같은 종류의 여러 데이터를 하나의 집합으로 저장할 수 있는 공간
- 구조체 : 서로 관련된 여러 데이터를 종류에 관계없이 하나의 집합으로 저장할 수 있는 공간
- 클래스 : 데이터와 함수의 결합(구조체 + 함수)
하나의 데이터를 저장하기 위해 변수, 같은 종류의 데이터를 보다 효율적으로 다루기 위해서 배열이라는 개념이 도입되었고, 구조체(structure)가 등장하여 자료형의 종류에 상관없이 서로 관계가 깊은 변수들을 하나로 묶어서 다룰 수 있도록 했다.
서로 관련된 변수들을 정의하고 이들에 대한 작업을 수행하는 함수들을 함께 정의한 것이 클래스이다. C언어에서는 문자열을 문자의 배열로 다루지만, Java에서는 String이라는 클래스로 문자열을 다룬다. 문자열을 클래스로 정의한 이유는 문자열과 문자열을 다루는데 필요한 함수들을 함께 묶기 위해서이다.
public final class String implements java.io.Serializable, Comparable {
private char[] value; // 문자열을 저장하기 위한 공간
public String replace(char oldChar, char newChar) {
...
char[] val = value; // 같은 클래스 내의 변수를 사용해서 작업을 한다.
...
...
}
}
위 코드는 String클래스의 실제 소스의 일부이다. 클래스 내부에 value라는 문자형 배열이 선언되어 있고, 문자열을 다루는 데 필요한 함수들을 함께 정의해 놓았다. 문자열의 일부를 뽑아내는 함수나 문자열의 길이를 알아내는 함수들은 항상 문자열을 작업대상으로 필요로 하기 때문에 문자열과 깊은 관계에 있으므로 함께 정의되어 있다.
사용자정의 타입(user-defined type)
프로그래밍언어에서 제공하는 자료형(primitive type)외에 프로그래머가 서로 관련된 변수들을 묶어서 하나의 타입으로 새로 추가하는 것을 사용자정의 타입(user-defined type)이라고 한다.
자바와 같은 객체지향언어에서는 클래스가 곧 사용자 정의 타입이다. 기본형의 개수는 8개로 정해져 있지만 참조형의 개수는 정해져 있지 않은 이유가 바로 프로그래머가 새로운 타입을 추가할 수 있기 때문이다.
시간을 표현하기 위해서 다음과 같이 3개의 변수를 선언해보자.
int hour; // 시
int minute; // 분
float second; // 초
만일 3개의 시간을 다뤄야한다면 변수의 개수가 3개로 늘어나는데, 다뤄야하는 시간의 개수가 늘어 날때마다 시, 분, 초를 위한 변수를 추가해줘야된다. 이 경우 다뤄야하는 데이터의 개수가 많으면 곤란하다.
int hour1, hour2, hour3, ...;
int minute1, minute2, minute3, ...;
float second1, second2, second3, ...;
이런 경우 배열을 활용해 볼 수 있다.
int[] hour = new int[n]; // n은 데이터의 개수
int[] minute = new int[n];
float[] second = new float[n];
배열로 처리하면 다뤄야하는 시간 데이터의 개수가 늘어나더라도 배열의 크기만 변경해주면 되므로, 변수를 매번 새로 선언해줘야하는 불편함과 복잡함이 사라진다. 그러나 하나의 시간을 구성하는 시, 분, 초가 서로 분리되어 있기 때문에 프로그램 수행과정에서 뒤섞여서 올바르지 않은 데이터가 될 가능성이 있다. 이런 경우에 시, 분, 초를 하나로 묶는 사용자정의 타입, 즉 클래스를 정의하여 사용해야한다.
class Time {
int hour;
int minute;
float second;
}
이제 시, 분, 초가 하나의 단위로 묶여서 다루어지기 때문에 다른 시간 데이터와 섞이는 일은 없겠지만, 시간 데이터에는 다음과 같은 추가 제약조건이 있다.
- 시, 분, 초는 모두 0보다 크거나 같아야 한다.
- 시의 범위는 0 ~ 23, 분과 초의 범위는 0 ~ 59이다.
이러한 조건들이 모두 코드에 반영될 때, 보다 정확한 데이터를 유지할 수 있다.
객체지향언어에서는 제어자와 메서드를 이용해서 이러한 조건들을 코드에 쉽게 반영할 수 있다.
public class Time {
private int hour;
private int minute;
private float second;
public int getHour() { return hour; }
public int getMinute() { return minute; }
public float seconde() { return second; }
public void setHour(int h) {
if(h < 0 || h > 23) return;
hour = h;
}
public void setMinute(int m) {
if(m < 0 || m > 59) return;
minute = m;
}
public void setSecond(float s) {
if(s < 0.0f || s > 59.99f) return;
second = s;
}
}
그래서 클래스를 만드는 방법이 뭔데?
다시 객체지향이론의 관점으로 돌아와서 클래스란 객체를 정의한 것이므로 클래스에는 객체의 모든 속성과 기능이 정의되어 있다. 클래스로부터 객체를 생성하면, 클래스에 정의된 속성과 기능을 가진 객체가 만들어지는 것이다.
속성과 기능은 같은 뜻을 가진 여러가지 단어가 있는데, 그 중에서 속성은 멤버변수, 기능은 메서드라는 용어로 자주 사용된다.
예를 들어 Tv클래스를 만든다고 할 때, TV의 속성은 전원상태, 크기, 길이, 높이, 색상, 볼륨, 채널 같은 것들이 있고, 기능으로는 켜기, 끄기, 볼륨 조절, 채널 변경 등이 있다. 이러한 내용을 토대로 코드를 작성하면 다음과 같다.
class Tv {
String color; // 색상
boolean power; // 전원상태
int channel; // 채널
void power() {
power = !power;
}
void channelUp() {
channel++;
}
void channelDown() {
channel--;
}
}
color, power, channel이라는 멤버변수가 선언되었고, power(), channelUp, channelDown()이라는 메서드가 선언되었다.
클래스는 위와 같은 방식으로 만들 수 있으며, 멤버변수와 메서드 외에 생성자라는 요소가 있다.
public, private, static 같은 것들은 무엇인가?
다른 사람들이 만든 코드를 읽다보면 메서드나 클래스 앞에 붙은 public, static과 같은 것들을 볼 수 있다. 이러한 것들을 제어자(modifier)라고 한다.
제어자는 클래스, 변수 또는 메서드의 선언부에 함께 사용되어 부가적인 의미를 부여한다. 제어자의 종류는 크게 접근 제어자와 그 외의 제어자로 나눌 수 있다.
- 접근 제어자 : public, protected, default, private
- 그 외 : static, final, abstract, native, transient, synchronized, volatile, strictfp
제어자는 하나의 대상에 대해서 여러 제어자를 조합하여 사용하는 것이 가능하지만, 접근 제어자는 한 번에 네 가지 중 하나만 선택해서 사용할 수 있다. 즉, 하나의 대상에 public과 private을 동시에 사용할 수 없다.
static - 클래스의, 공통적인
static은 ‘클래스의’ 또는 ‘공통적인’이라는 의미를 가진다. 인스턴스변수는 하나의 클래스로부터 생성되었더라도 각기 다른 값을 유지하지만, 클래스변수(static멤버변수)는 인스턴스에 관계없이 같은 값을 갖는다. 그 이유는 하나의 변수를 모든 인스턴스가 공유하기 때문이다.
static이 붙은 멤버변수와 메서드, 그리고 초기화 블럭은 인스턴스가 아닌 클래스에 관계된 것이기 때문에 인스턴스를 생성하지 않고도 사용할 수 있다.
인스턴스 메서드와 static메서드의 근본적인 차이는 메서드 내에 인스턴스 멤버를 사용하는가의 여부에 있다.
| 제어자 | 대 상 | 의 미 |
| static | 멤버변수 | - 모든 인스턴스에 공통적으로 사용되는 클래스변수가 된다. - 클래스변수는 인스턴스를 생성하지 않고도 사용 가능하다. - 클래스가 메모리에 로드될 때 생성된다. |
| 메서드 | - 인스턴스를 생성하지 않고도 호출이 가능한 static 메서드가 된다. - static메서드 내에서는 인스턴스멤버들을 직접 사용할 수 없다. |
인스턴스 멤버를 사용하지 않는 메서드는 static을 붙여서 static메서드로 선언하면 인스턴스를 생성하지 않고도 호출이 가능해 편리하고 속도도 빠르니 고려해보자.
class StaticTest {
static int width = 200; // static 변수
static int height = 120; // static 변수
static { // 클래스 초기화 블럭
// static변수의 복잡한 초기화 수행
}
static int max(int a, int b) { // static 메서드
return a > b ? a : b;
}
}
static 초기화 블럭은 클래스가 메모리에 로드될 때 단 한번만 수행되며, 주로 static변수를 초기화하는데 사용된다.
final - 마지막의, 변경될 수 없는
final은 ‘마지막의’ 또는 ‘변경될 수 없는’의 의미를 가지고 있으며 거의 모든 대상에 사용될 수 있다.
변수에 사용되면 값을 변경할 수 없는 상수가 되며, 메서드에 사용되면 오버라이딩을 할 수 없게 되고 클래스에 사용되면 자신을 확장하는 자손클래스를 정의하지 못하게 된다.
| 제어자 | 대 상 | 의 미 |
| final | 클래스 | 변경될 수 없는 클래스, 확장될 수 없는 클래스가 된다. 따라서 final로 지정된 클래스는 다른 클래스의 조상이 될 수 없다. |
| 메서드 | 변경될 수 없는 메서드, final로 지정된 메서드는 오버라이딩을 통해 재정의 될 수 없다. | |
| 멤버변수 | 변수 앞에 final이 붙으면, 값을 변경할 수 없는 상수가 된다. | |
| 지역변수 |
final class FinalTest { // 조상이 될 수 없는 클래스
final int MAX_SIZE = 10; // 값을 변경할 수 없는 멤버변수(상수)
final void getMaxSize() { // 오버라이딩할 수 없는 메서드(변경불가)
final int LV = MAX_SIZE; // 값을 변경할 수 없는 지역변수(상수)
return MAX_SIZE;
}
}
생성자를 이용한 final멤버변수의 초기화
final이 붙은 변수는 상수이므로 일반적으로 선언과 동시에 초기화를 동시에 하지만, 인스턴스변수의 경우 생성자에서 초기화 되도록 할 수 있다.
클래스 내에 매개변수를 갖는 생성자를 선언하여, 인스턴스를 생성할 때 final이 붙은 멤버변수를 초기화하는데 필요한 값을 생성자의 매개변수로부터 제공받는 것이다. 이 기능을 활용하면 각 인스턴스마다 final이 붙은 멤버변수가 다른 값을 갖도록 하는 것이 가능하다.
class Card {
final int NUMBER; // 상수지만 선언과 함께 초기화 하지 않고
final String KIND; // 생성자에서 단 한번만 초기화할 수 있다.
static int width = 100;
static int height = 250;
// 매개 변수로 넘겨받은 값으로 KIND와 NUMBER를 초기화한다.
Card(String kind, int num) {
KIND = kind;
NUMBER = num;
}
Card() {
this("HEART", 1);
}
public String toString() {
return KIND + " " + NUMBER;
}
}
class FinalCardTest {
public static void main(String[] args) {
Card c = new Card("HEART", 10);
// c.NUMBER = 5; Error. cannot assign a value to final variable NUMBER
System.out.println(c.KIND);
System.out.println(c.NUMBER);
System.out.println(c); // System.out.println(c.toString());
}
}
abstract - 추상의, 미완성의
‘미완성’의 의미를 가지고 있는 abstract은 메서드의 선언부만 작성하고 실제 수행내용은 구현하지 않은 추상 메서드를 선언하는데 사용된다. 그리고 클래스에 사용되어 클래스 내에 추상메서드가 존재한다는 것을 쉽게 알 수 있게 한다.
| 제어자 | 대 상 | 의 미 |
| abstract | 클래스 | 클래스 내에 추상 메서드가 선언되어 있음을 의미한다. |
| 메서드 | 선언부만 작성하고 구현부는 작성하지 않은 추상 메서드임을 알린다. |
추상 클래스는 아직 완성되지 않은 메서드는 존재하는 ‘미완성 설계도’이므로 인스턴스를 생성할 수 없다.
abstract class AbstractTest { // 추상 클래스(추상 메서드를 포함한 클래스)
abstract void move(); // 추상 메서드(구현부가 없는 메서드)
}
접근 제어자
접근 제어자는 멤버 또는 클래스에 사용되어, 해당하는 멤버 또는 클래스를 외부에서 접근하지 못하도록 제한하는 역할을 한다. 접근 제어자가 default임을 알리기 위해 실제로 default를 붙이지는 않는다. 클래스나 멤버변수, 메서드, 생성자에 접근 제어자가 지정되어 있지 않다면, 접근 제어자가 default임을 뜻한다.
- 접근 제어자가 사용될 수 있는 곳 - 클래스, 멤버변수, 메서드, 생성자
- private : 같은 클래스 내에서만 접근이 가능하다.
- default : 같은 패키지 내에서만 접근이 가능하다.
- protected : 같은 패키지 내에서, 그리고 다른 패키지의 자손 클래스에서 접근이 가능하다.
- public : 접근 제한이 없다.
public은 접근 제한이 전혀 없고, private은 같은 클래스 내에서만 사용하도록 제한하는 가장 높은 제한이다. 그리고 default는 같은 패키지 내의 클래스에서만 접근이 가능하도록 하는 것이다.
protected는 패키지에 관계없이 상속관계에 있는 자손클래스에서 접근할 수 있도록 하는 것이 제한목적이지만, 같은 패키지 내에서도 접근이 가능하다.
| 대 상 | 사용가능한 접근 제어자 |
| 클래스 | public, (default) |
| 메서드 | public, protected, (default), private |
| 멤버변수 | |
| 지역변수 | 없 음 |
제어자(modifier)의 조합
| 대 상 | 사용가능한 제어자 |
| 클래스 | public, (default), final, abstract |
| 메서드 | 모든 접근 제어자, final, abstract, static |
| 멤버변수 | 모든 접근 제어자, final, static |
| 지역변수 | final |
제어자를 조합할 때 주의해야할 사항은 다음과 같다.
- 메서드에 static과 abstract를 함께 사용할 수 없다.
static메서드는 몸통이 있는 메서드에만 사용할 수 있기 때문이다. - 클래스에 abstract와 final을 동시에 사용할 수 없다.
클래스에 사용되는 final은 클래스를 확장할 수 없다는 의미이고 abstract는 상속을 통해서 완성되어야 한다는 의미이므로 서로 모순되기 때문이다. - abstract메서드의 접근 제어자가 private일 수 없다.
abstract메서드는 자손클래스에서 구현해주어야 하는데 접근 제어자가 private이면, 자손클래스에서 접근할 수 없기 때문이다. - 메서드에 private과 final을 같이 사용할 필요는 없다.
접근 제어자가 private인 메서드는 오버라이딩될 수 없기 떄문이다. 둘 중 하나만 사용해도 의미가 충분하다.
객체 만드는 방법 (new 키워드 이해하기)
객체? 인스턴스?
클래스에서 객체에 대해서 계속 언급했는데 그렇다면 객체는 뭘까? 객체의 사전적 정의는 ‘실제로 존재하는 것’이다. 우리가 주변에서 볼 수 있는 책상, 자동차, 의자 같은 사물들이 곧 객체인 것이다. 객체지향이론에서는 사물과 같은 유형적인 것 뿐만 아니라, 개념이나 논리와 같은 무형적인 것들도 객체로 간주한다.
프로그래밍에서의 객체는 클래스에 정의된 내용대로 메모리에 생성된 것을 뜻한다.
- 객체의 정의 : 실제로 존재하는 것. 사물 또는 개념
- 객체의 용도 : 객체가 가지고 있는 기능과 속성에 따라 다름
클래스로부터 객체를 만드는 과정을 클래스의 인스턴스화(instantiate)라고 하며, 어떤 클래스로부터 만들어진 객체를 그 클래스의 인스턴스(instance)라고 한다.
결국 인스턴스는 객체와 같은 의미이지만, 객체는 모든 인스턴스를 대표하는 포괄적인 의미를 가지고 있으며, 인스턴스는 어떤 클래스로부터 만들어진 것인지를 강조하는 보다 구체적인 의미를 가지고 있다.
인스턴스와 객체는 같은 의미이므로 두 용어의 사용을 엄격히 구분할 필요는 없지만, 문맥에 따라 구별하여 사용하는 것이 좋다.
객체는 속성과 기능, 두 종류의 구성요소로 이루어져 있으며, 일반적으로 객체는 다수의 속성과 다수의 기능을 갖는다. 즉, 속성과 기능의 집합이라고 할 수 있다.
객체가 가지고 있는 속성과 기능을 그 객체의 멤버(구성원, member)라 한다.
인스턴스의 생성과 사용
인스턴스(객체)를 생성하고 사용하는 것에 대해 예제를 통해 알아보자. 일반적으로 클래스로부터 인스턴스를 생성하는 방법은 다음과 같다.
클래스명 변수명; // 클래스의 객체를 참조하기 위한 참조변수 선언
변수명 = new 클래스명(); // 클래스의 객체를 생성 후, 객체의 주소를 참조변수에 저장
new 키워드를 사용하여 객체의 주소를 참조변수에 저장하는데 JVM의 heap 영역에 객체가 생성되고 stack 영역에서는 객체의 주소값만 가지고 있게 된다.
이제 예제를 살펴보자.
class Target {
String str;
int num;
void up() { ++num; }
void down() { --num; }
}
class App {
public static void main(String[] args) {
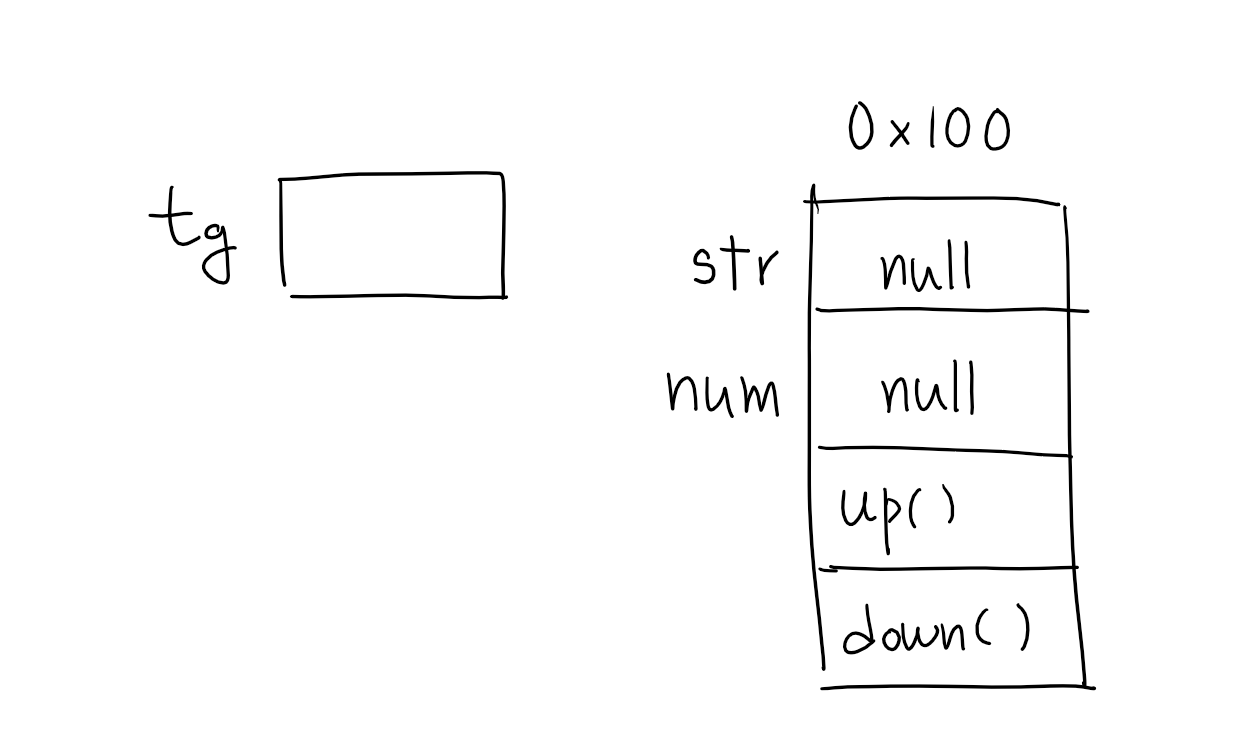
Target tg = new Target();
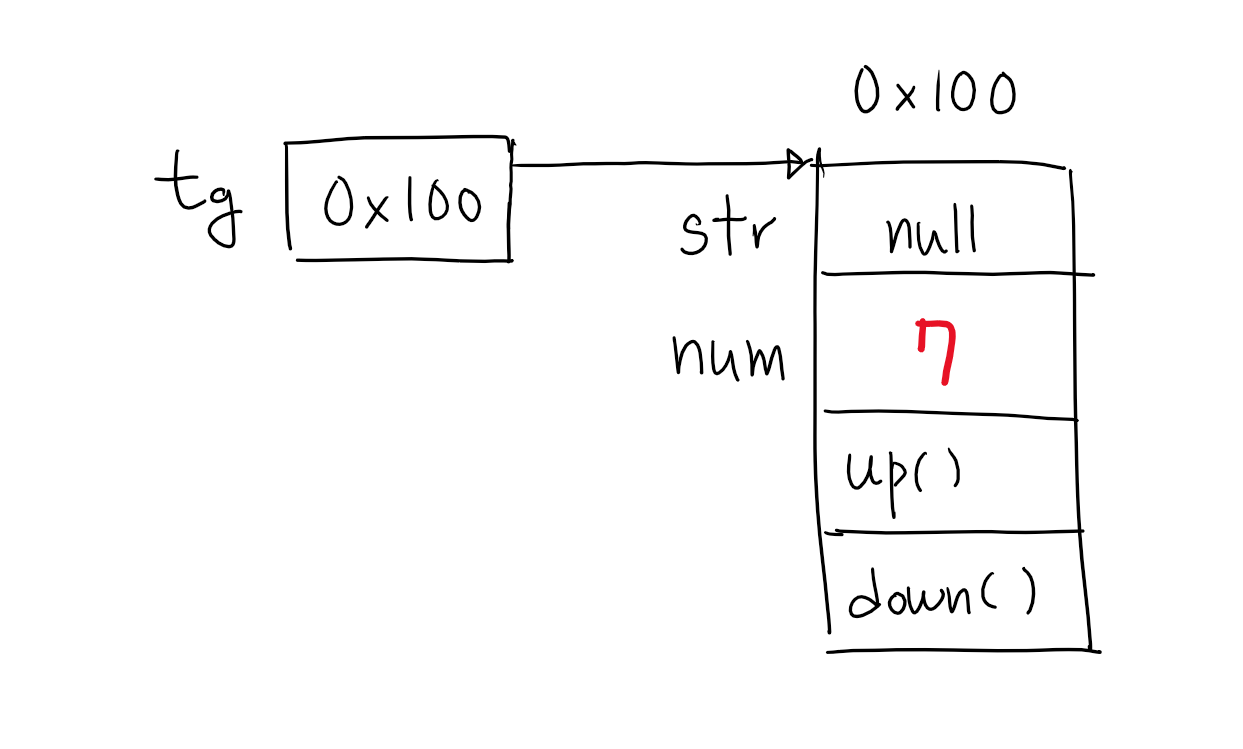
tg.num = 7;
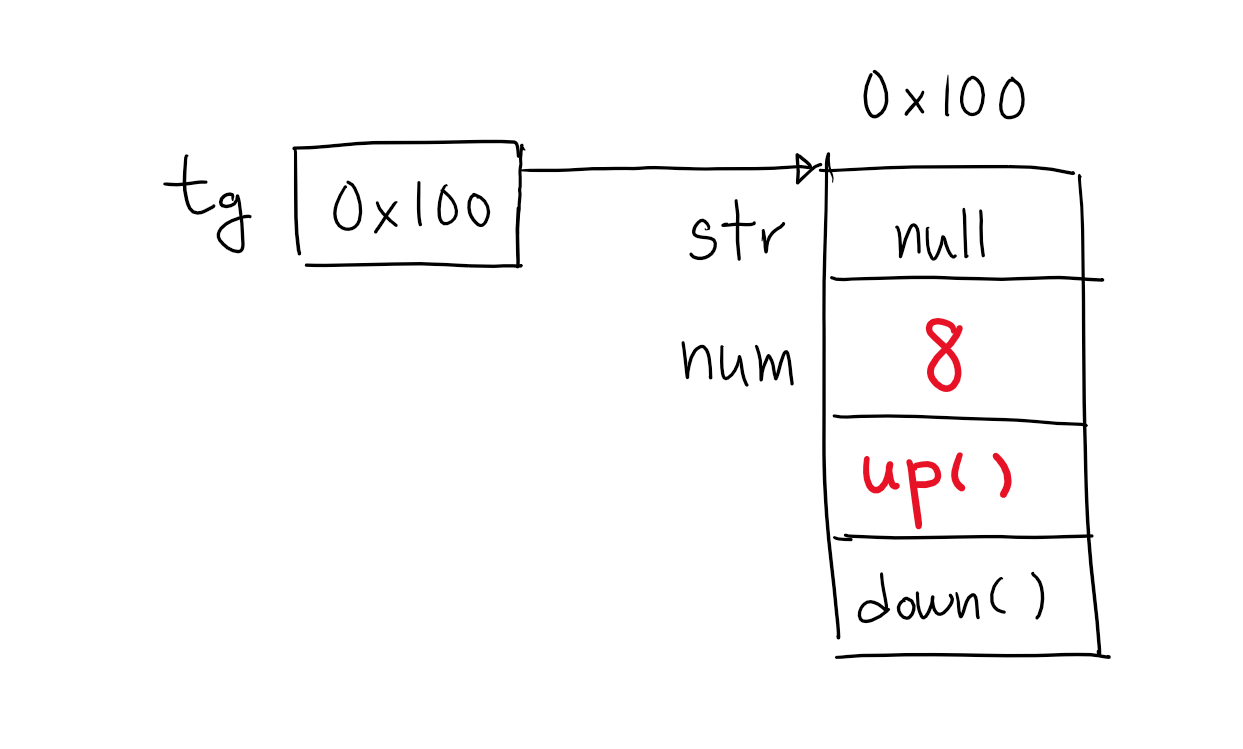
tg.up();
System.out.println(tg.num);
}
}

Target클래스로부터 인스턴스를 생성하고 속성과 메서드를 사용한 예제이다. 각 부분별로 살펴보자.
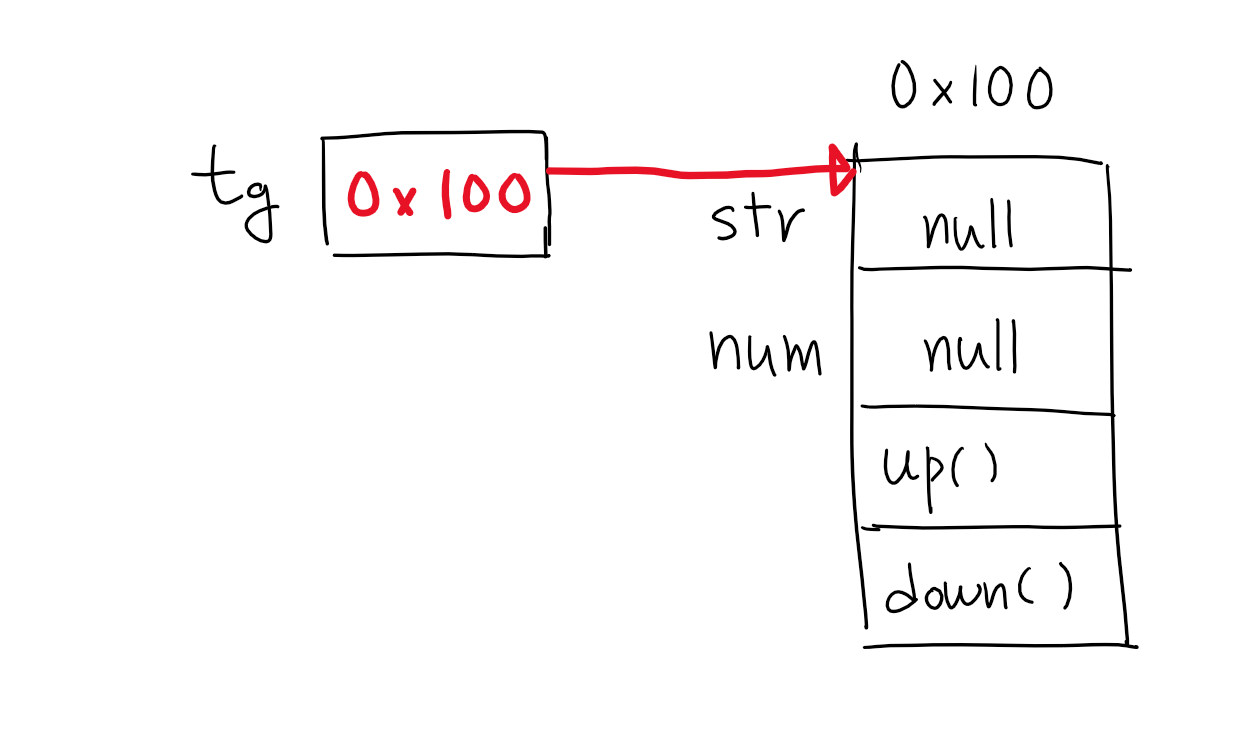
Target tg = new Target();
Target클래스 타입의 참조변수 tg를 선언했다. 연산자 new에 의해 Target클래스의 인스턴스가 메모리의 빈 공간에 생성되는데, new를 사용하기 전 tg만 선언되었을 때는 인스턴스가 생성되지 않았기 때문에 아무것도 할 수 없다.
멤버변수는 각 자료형에 해당하는 기본값으로 초기화 된다.
이후 대입 연산자에 의해서 생성된 객체의 주소값이 참조변수 tg에 저장된다. 이제부터 tg를 통해 Target인스턴스에 접근할 수 있다. 인스턴스를 다루기 위해서는 참조변수가 반드시 필요하다.
tg.num = 7;
참조변수 tg에 저장된 주소에 있는 인스턴스의 멤버변수 num에 7을 저장한다. 인스턴스의 멤버변수(속성)을 사용하려면 ‘참조변수.멤버변수’와 같이 하면 된다.
tg.up();
참조변수 tg가 참조하고 있는 Target인스턴스의 up메서드를 호출한다. up메서드는 멤버변수 num에 저장되어 있는 값을 1 증가시킨다.
이처럼 인스턴스는 참조변수를 통해서만 다룰 수 있으며, 참조변수의 타입은 인스턴스의 타입과 일치해야한다. 인스턴스를 여러 개 생성했을 경우, 같은 클래스로부터 생성되었을지라도 각 인스턴스의 속성(멤버변수)은 서로 다른 값을 유지할 수 있으며, 메서드의 내용은 모든 인스턴스에 대해 동일하다.
메서드 정의하는 방법
메서드란?
메서드(method)는 특정 작업을 수행하는 일련의 문장들을 하나로 묶은 것이다. 수학의 함수와 유사하며 어떤 값을 입력하면 이 값으로 작업을 수행해서 결과를 반환한다. 물론 수학의 함수와 달리 입력값 또는 출력값이 없을 수도 있고, 심지어 둘 다 없을 수도 있다.
메서드가 작업을 처리하는 과정은 몰라도 된다. 그저 작업을 수행하는데 필요한 값만 넣고 원하는 결과를 얻으면 된다. 그래서 메서드를 내부가 보이지 않는 ‘블랙박스(black box)’라고도 한다.
그러면 왜 메서드를 사용하는가?
메서드를 통해서 얻는 이점은 여러가지 있다. 그 중에서 대표적인 이점이 세 가지 정도가 있는데 이 장점들을 염두하고 공부를 해보자.
-
높은 재사용성(reusability)
Java API에서 제공하는 메서드들을 사용하면서 경험했듯이 한번 만들어 놓은 메서드는 몇 번이고 호출이 가능하고, 다른 프로그램에서도 사용이 가능하다. -
중복된 코드 제거
프로그램을 작성하다보면, 같은 내용의 문장들이 여러 곳에서 반복해 나타날 때가 있다. 반복되는 문장들을 묶어서 하나의 메서드로 작성해 두면, 메서드를 호출하는 한 문장으로 대체할 수 있다. 그러면 전체 소스코드의 길이도 짧아지고 수정해야할 부분도 줄어들어 오류가 발생할 가능성도 줄어든다. -
프로그램의 구조화 처음 프로그램을 작성할 때 main메서드 안에 모든 문장을 넣는 식으로 배우게 된다. 적당히 100줄 정도의 작은 프로그램을 작성할 때는 괜찮지만, 규모가 큰 프로그램을 작성할 떄는 좋지 않다. 큰 규모의 프로그램에서는 문장들을 작업단위로 나눠서 여러 개의 메서드에 담아 프로그램의 구조를 단순화 시키는 것이 중요하다.
main메서드에서는 프로그램 전체의 흐름이 한 눈에 들어올 정도로 단순하게 구조화하고 세세한 부분은 메서드로 만드는 것이다.
메서드의 선언과 구현
메서드는 크게 선언부(header, 머리)와 구현부(body, 몸통)으로 나눌 수 있다. 메서드를 정의한다는 것은 선언부와 구현부를 작성하는 것을 뜻하며 다음과 같은 형식으로 정의한다.

메서드 선언부(method declaration, method header)
메서드 선언부는 메서드의 이름과 매개변수 선언 그리고 반환타입으로 구성되어 있으며, 메서드가 작업을 수행하기 위해 어떤 값들을 필요로 하고 작업 결과로 어떤 타입의 값을 반환하는지에 대한 정보를 제공한다.
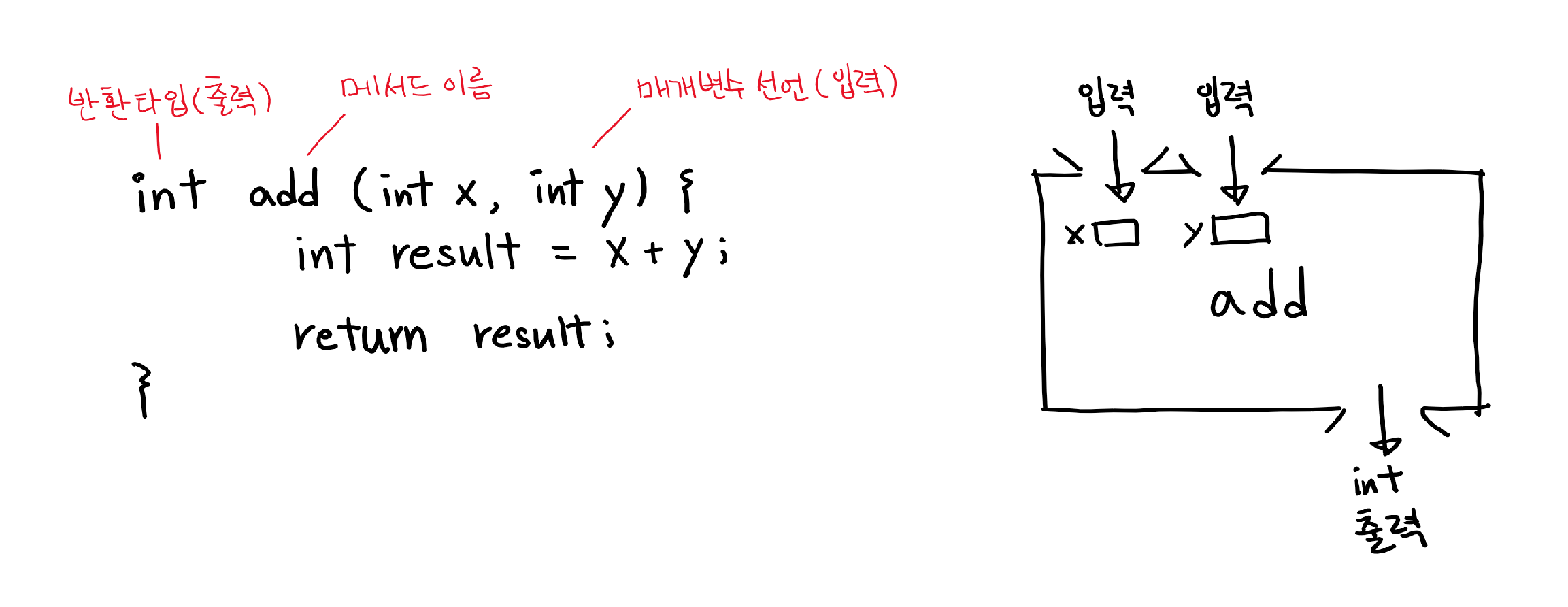
메서드의 선언부는 이 후에 변경사항이 발생하지 않도록 신중하게 작성해야 한다. 메서드의 선언부를 변경하게 되면, 그 메서드가 호출되는 모든 곳도 같이 변경해야 하기 때문이다.
-
매개변수 선언(parameter declaration)
매개변수는 메서드가 작업을 수행하는데 필요한 값들(입력)을 제공받기 위한 것이며, 필요한 값의 개수만큼 변수를 선언하며 각 변수 간의 구분은 쉼표 ‘,’를 사용한다. 일반적인 변수선언과 달리 두 변수의 타입이 같아도 변수의 타입을 생략할 수 없다.
선언할 수 있는 매개변수의 개수는 거의 제한이 없지만, 입력해야할 값의 개수가 많은 경우에는 배열이나 참조변수를 사용하면 된다. 값을 입력받을 필요가 없다면 괄호() 안을 비워두면 된다.
참고로 매개변수도 메서드 내에 선언된 것으로 간주되므로 지역변수(local variable)이다. -
메서드의 이름(method name)
메서드의 이름도 변수의 명명규칙대로 작성하면 된다. 메서드는 특정 작업을 수행하므로 메서드의 이름은 동사인 경우가 많으며, 기능을 쉽게 알 수 있도록 짓는게 좋다. -
반환타입(return type)
메서드의 작업수행 결과(출력)인 반환값(return value)의 타입을 적는다. 반환값이 없는 경우 반환타입으로 ‘void’를 적어야한다.
메서드의 구현부
메서드의 선언부 다음에 오는 괄호 { }를 ‘메서드의 구현부’라고 하는데, 여기에 메서드를 호출했을 때 수행될 문장들을 넣는다.
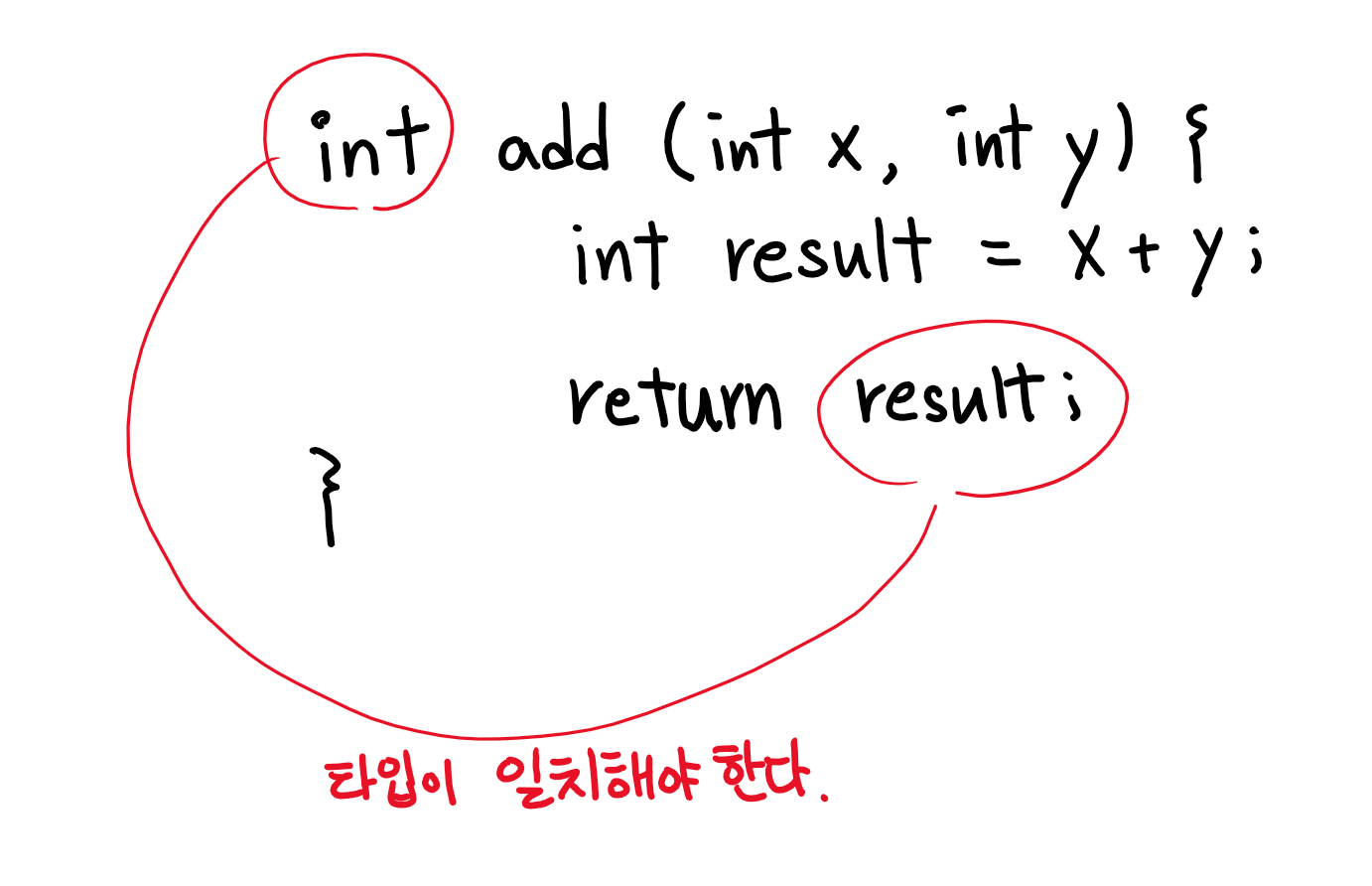
- return문
메서드의 반환타입이 ‘void’가 아닌 경우, 구현부 안에return 반환값;이 반드시 포함되어 있어야 한다. 이 문장은 작업을 수행한 결과인 반환값을 호출한 메서드로 전달하는데, 값의 타입은 반환타입과 일치하거나 자동 형변환이 가능한 것이어야 한다.
여러개의 변수를 선언할 수 있는 매개변수와 달리 return문은 단 하나의 값만 반환할 수 있는데, 메서드로의 입력(매개변수)은 여러 개일 수 있어도 출력(반환값)은 최대 하나만 허용하는 것이다.
- 지역변수
메서드 내에 선언된 변수들은 그 메서드 내에서만 사용할 수 있으므로 서로 다른 메서드라면 같은 이름의 변수를 선언해도 된다. 이처럼 메서드 내에 선언된 변수를 ‘지역변수(local variable)’라고 한다.
아래 코드에 정의된 add와 multiply에 각기 선언된 변수 x, y, result는 이름만 같은 서로 다른 변수이다.
int add(int x, int y) {
int result = x + y;
return result;
}
int multiply(int x, int y) {
int result = x * y;
return result;
}
메서드의 호출
메서드를 정의하는 방법에 대해 알아봤다. 하지만 메서드를 정의했어도 호출되지 않으면 아무 일도 일어나지 않는다. 메서드를 호출해야 구현부의 문장들이 수행되기 때문이다.
메서드이름(값1, 값2, ...); // 메서드 호출 방법
메서드의 호출 방법은 위와 같고 main메서드는 프로그램 실행 시 OS에 의해 자동적으로 호출된다.
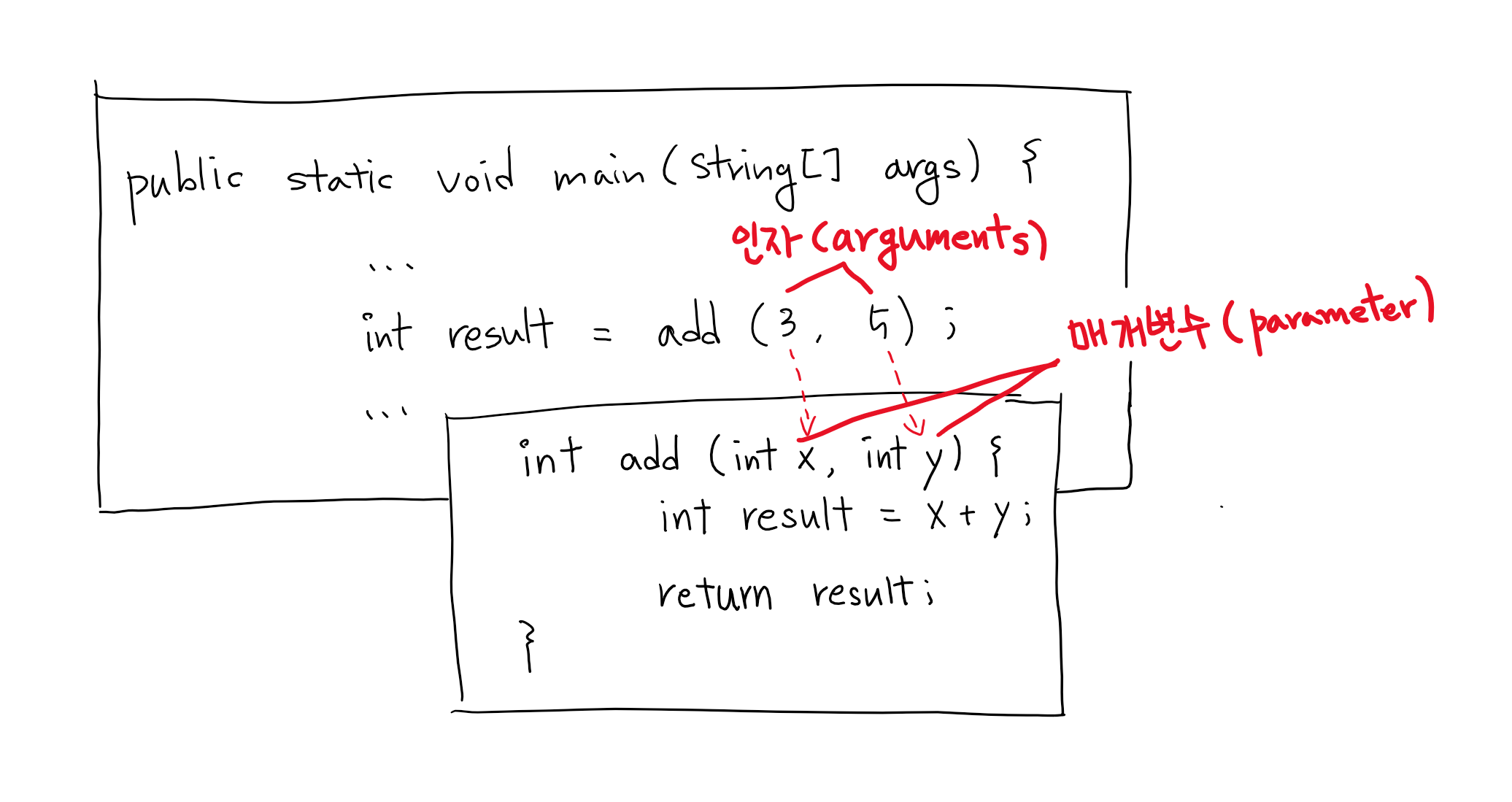
인자(argument)와 매개변수(parameter)
메서드를 호출할 때 괄호 안에 지정해준 값들을 ‘인자(argument)’ 또는 ‘인수’라고 하는데, 인자의 개수와 순서는 호출된 메서드에 선언된 매개변수와 일치해야 한다. 또한 인자는 메서드가 호출되면서 매개변수에 대입되므로, 인자의 타입은 매개변수의 타입과 일치하거나 자동 형변환이 가능한 것이어야 한다.
만일 메서드에 선언된 매개변수의 개수보다 많은 값을 괄호에 넣거나 타입이 다른 값을 넣으면 컴파일러가 에러를 발생시킨다.
int result = add(1, 2, 3); // Error. 개수가 다름
int result = add(1.0, 2.0); // Error. 타입이 다름
반환타입이 void가 아닌 경우, 메서드가 작업을 수행하고 반환한 값을 대입연산자로 변수에 저장하는 것이 보통이지만, 저장하지 않아도 문제가 되지 않는다.
int result = add(3, 5); // int add(int x, int y)의 호출결과를 result에 저장
add(3, 5); // Ok. 반환한 결과를 사용하지 않아도 된다.
생성자 정의하는 방법
생성자란?
생성자는 인스턴스가 생성될 때 호출되는 인스턴스 초기화 메서드이다. 인스턴스 변수의 초기화 작업에 주로 사용되며, 인스턴스 생성 시에 실행되어야 할 작업을 위해서도 사용된다.
생성자는 메서드처럼 클래스 내에 선언되며, 구조도 메서드와 유사하지만 리턴값이 없다. 하지만 리턴값이 없음을 뜻하는 void를 사용하지는 않는다. 생성자도 메서드이기 떄문에 void를 붙여야 하지만, 모든 생성자가 리턴값이 없기 때문에 생략할 수 있는 것이다.
생성자의 조건과 정의
생성자의 조건은 다음과 같다.
- 생성자의 이름은 클래스의 이름과 같아야 한다.
- 생성자는 리턴 값이 없다.
생성자도 오버로딩이 가능하므로 하나의 클래스에 여러 개의 생성자가 존재할 수 있다.
클래스이름 (타입 변수명, 타입 변수명, ... ) {
// 인스턴스 생성 시 수행될 코드,
// 주로 인스턴스 변수의 초기화 코드를 적는다.
}
한 가지 주의해야 할 점은 연산자 new가 인스턴스를 생성하는 것이지 생성자가 인스턴스를 생성하는 것이 아니다. 생성자는 단순히 인스턴스 변수들의 초기화에 사용되는 조금 특별한 메서드일 뿐이다.
Target tg = new Target();
위 코드가 수행되는 과정을 단계별로 나누어보면 다음과 같다.
- 연산자 new에 의해서 메모리(heap)에 Target클래스의 인스턴스가 생성된다.
- 생성자 Target()이 호출되어 수행된다.
- 연산자 new의 결과로, 생성된 Target인스턴스의 주소가 반환되어 참조변수 tg에 저장된다.
인스턴스를 생성하기 위해서 사용해왔던 ‘클래스이름()’이 바로 생성자이다! 인스턴스를 생성할 때는 반드시 클래스 내에 정의된 생성자 중의 하나를 선택하여 지정해주어야 한다.
기본 생성자(default constructor)
모든 클래스에는 반드시 하나 이상의 생성자가 정의되어 있어야 한다. 그러나 지금까지 클래스에 생성자를 정의하지 않고도 인스턴스를 생성할 수 있었던 이유는 컴파일러가 제공하는 ‘기본 생성자(default constructor)’ 덕분이다.
컴파일을 할 때, 소스파일(*.java)의 클래스에 생성자가 하나도 정의되어 있지 않은 경우 컴파일러는 자동적으로 아래와 같은 기본 생성자를 추가하여 컴파일 한다.
// 클래스이름() { }
Target() { }
컴파일러가 자동적으로 추가해주는 기본 생성자는 매개변수도 없고 아무런 내용도 없는 간단한 것이다. 참고로 클래스의 ‘접근 제어자(Access Modifier)’가 public인 경우에는 기본 생성자로 ‘public 클래스이름() { }’이 추가된다.
특별히 인스턴스 초기화 작업이 요구되지 않는다면 생성자를 정의하지 않고 컴파일러가 제공하는 기본 생성자를 사용하는 것도 좋다.
class Date1 {
int value;
}
class Data2 {
int value;
Data2(int x) {
value = x;
}
}
class Main {
public static void main(String[] args) {
Data1 d1 = new Data1();
Data2 d2 = new Data2();
}
}
위 코드를 실행하면 compile error가 발생한다. Data2에서 Data2()를 찾을 수 없다는 내용의 에러메시지가 출력되는데, 당연하게도 이는 Data2에 생성자 Data2()가 정의되어 있지 않기 때문이다.
Data1의 인스턴스를 생성하는 코드는 에러가 없는데, 왜 Data2의 인스턴스를 생성하는 코드에서 에러가 발생할까?
이유는 Data1에는 정의되어 있는 생성자가 하나도 없으므로 컴파일러가 기본 생성자를 추가해주었지만, Data2에서는 이미 Data2(int x)가 정의되어 있으므로 기본 생성자가 추가되지 않는다.
컴파일러가 자동적으로 기본 생성자를 추가해주는 경우는 클래스 내에 생성자가 하나도 없을 때뿐이다.
매개변수가 있는 생성자
생성자도 메서드처럼 매개변수를 선언하여 호출 시 값을 넘겨받아 인스턴스의 초기화 작업에 사용할 수 있다.
class User {
String name;
String language;
User() { }
User(String n, String l) {
name = c;
language = l;
}
}
User인스턴스를 생성할 때, User()를 사용한다면 인스턴스를 생성한 후에 인스턴스변수들을 따로 초기화해주어야 하지만, 매개변수가 있는 생성자 User(String n, String l)을 사용한다면 인스턴스를 생성하는 동시에 원하는 값으로 초기화를 할 수 있게 된다.
this 키워드 이해하기
같은 클래스의 멤버들 간에 서로 호출할 수 있는 것처럼 생성자 간에도 서로 호출이 가능하다. 단, 다음 두 조건을 만족시켜야 한다.
- 생성자의 이름으로 클래스이름 대신 this를 사용한다.
- 한 생성자에서 다른 생성자를 호출할 때는 반드시 첫 줄에서만 호출이 가능하다.
아래 코드는 두 조건을 모두 만족하지 못했기 때문에 에러가 발생한다.
User(String name) {
language = "java";
User(name, "java"); // 에러1. 두 번째 줄에서 생성자 호출
} // 에러2. this(name, "java");로 해야함
생성자 내에서 다른 생성자를 호출할 때는 클래스이름인 ‘User’ 대신 ‘this’를 사용하지 않았고, 생성자 호출이 첫 번째 줄이 아닌 두 번째 줄이다.
생성자에서 다른 생성자를 첫 줄에서만 호출이 가능하도록 한 이유는 생성자 내에서 초기화 작업도중에 다른 생성자를 호출하게 되면, 호출된 다른 생성자 내에서도 멤버변수들의 값을 초기화를 할 것이므로 다른 생성자를 호출하기 이전의 초기화 작업이 무의미해질 수 있기 때문이다.
그래서 this가 무엇입니까?
‘this’는 참조변수로 인스턴스 자신을 가리킨다. 참조변수를 통해 인스턴스의 멤버에 접근할 수 있는 것처럼, ‘this’로 인스턴스변수에 접근할 수 있는 것이다.
하지만, ‘this’를 사용할 수 있는 것은 인스턴스멤버뿐이다. static메서드에서는 인스턴스멤버들을 사용할 수 없는 것처럼, ‘this’ 역시 사용할 수 없다.
생성자를 포함한 모든 인스턴스메서드에는 자신이 관련된 인스턴스를 가리키는 참조변수 ‘this’가 지역변수로 숨겨진 채로 존재한다.
정리!
- this
인스턴스 자신을 가리키는 참조변수. 인스턴스의 주소가 저장되어 있다.
모든 인스턴스 메서드에 지역변수로 숨겨진 채 존재한다. - this( ), this(매개변수)
생성자. 같은 클래스의 다른 생성자를 호출할 때 사용한다.
this와 this( )는 비슷하게 생겼지만 완전히 다른 것이다. this는 ‘참조변수’이고, this( )는 ‘생성자’이다.
과제
Node클래스
BFS
DFS
Reference
Comments
JAVA STUDY HALLE 의 다른 글
-
15주차 피드백 06 Mar 2021
-
15주차 과제: 람다식. 28 Feb 2021
-
14주차 피드백 27 Feb 2021
-
14주차 과제: 제네릭. 22 Feb 2021
-
13주차 피드백 20 Feb 2021
-
13주차 과제: I/O. 08 Feb 2021
-
12주차 피드백 06 Feb 2021
-
12주차 과제: 애노테이션. 01 Feb 2021
-
11주차 피드백 30 Jan 2021
-
11주차 과제: Enum. 24 Jan 2021
-
10주차 피드백 23 Jan 2021
-
10주차 과제: 멀티쓰레드 프로그래밍. 18 Jan 2021
-
9주차 피드백 16 Jan 2021
-
9주차 과제: 예외 처리. 10 Jan 2021
-
8주차 피드백 09 Jan 2021
-
8주차 과제: 인터페이스. 03 Jan 2021
-
7주차 피드백 02 Jan 2021
-
7주차 과제: 패키지. 28 Dec 2020
-
6주차 피드백 27 Dec 2020
-
6주차 과제: 상속. 21 Dec 2020
-
5주차 피드백 20 Dec 2020
-
5주차 과제: 클래스. 14 Dec 2020
-
4주차 피드백 13 Dec 2020
-
4주차 과제: 제어문. 30 Nov 2020
-
3주차 피드백 29 Nov 2020
-
3주차 과제: 연산자. 22 Nov 2020
-
2주차 피드백 21 Nov 2020
-
2주차 과제: 자바 데이터 타입, 변수 그리고 배열. 15 Nov 2020
-
1주차 피드백 15 Nov 2020
-
1주차 과제: JVM은 무엇이며 자바 코드는 어떻게 실행하는 것인가. 08 Nov 2020