
Written by
Sunwoo Han
on
on
너비 우선 탐색(breadth-first search, BFS)
너비 우선 탐색(BFS, breadth-first search)
BFS란?
너비 우선 탐색은 시작점에서 가까운 정점부터 순서대로 방문하는 탐색 알고리즘이다. 각 정점을 방문할 때마다 모든 인접 정점들을 검사한다. 이 중 처음 보는 정점을 발견하면 이 정점을 방문 예정이라고 기록해 둔 뒤, 별도의 위치에 저장한다. 인접한 정점을 모두 검사하고 나면, 지금까지 저장한 목록에서 다음 정점을 꺼내서 방문한다. 이를 위해서는 목록에 먼저 넣은 정점을 항상 먼저 꺼내야 한다. 따라서 정점 목록으로 큐를 사용하면 좋다.
예시
vector<vector<int> > adj; // 그래프의 인접 리스트
vector<int> bfs(int start) { // start에서 시작해 각 정점의 방문 순서를 반환
vector<bool> discovered(adj.size(), false); // 각 정점의 방문 여부
queue<int> q; // 방문할 정점 목록
// 정점의 방문 순서
vector<int> order;
discovered[start] = true;
q.push(start);
while(!q.empty()) {
int here = q.front();
q.pop();
order.push_back(here); // here를 방문
for(int i = 0; i < adj[here].size(); i++) { // 인접한 모든 정점을 검사
int there = adj[here][i];
if(!discovered[there]) { // 처음 방문한 정점이면 목록에 추가
q.push(there);
discovered[there] = true;
}
}
}
return order;
}
GIF로 확인하는 BFS
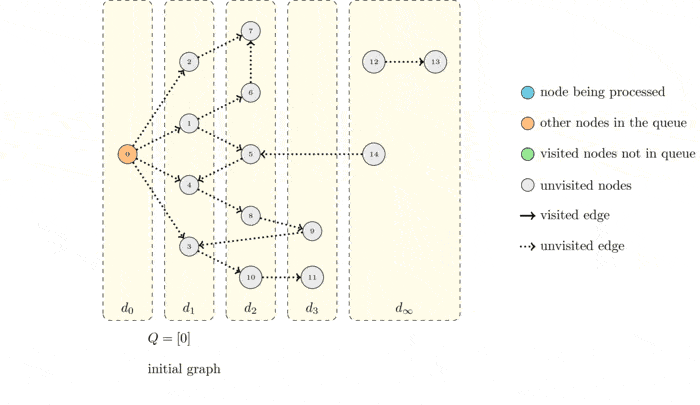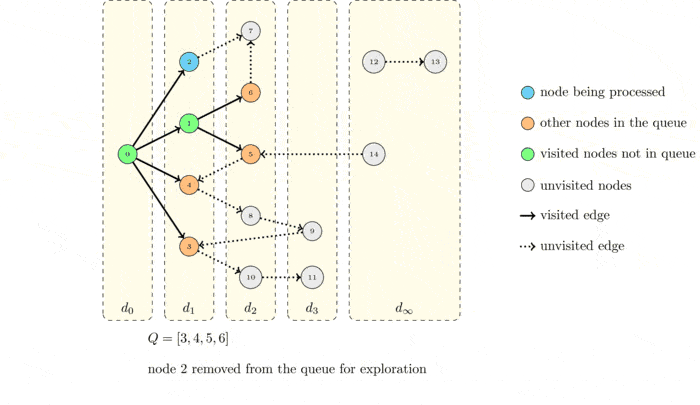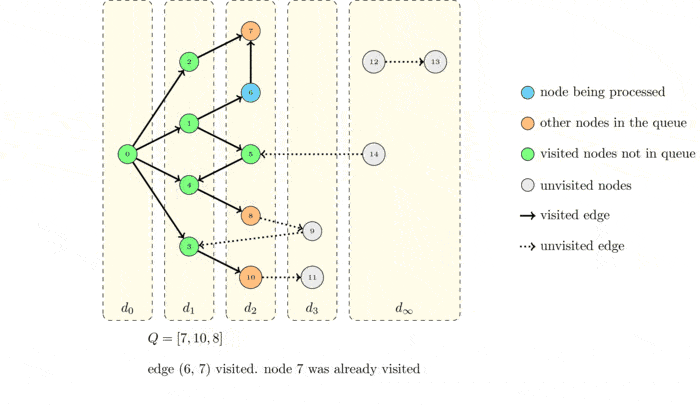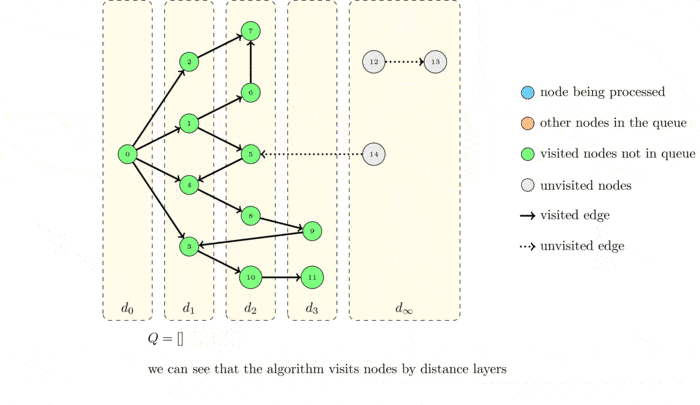
시간복잡도
DFS와 같다.
- 인접 리스트를 사용할 경우
- 한 정점마다 한 번씩 호출하므로, |V|번 호출한다.
- 모든 정점에 대해 수행하고 나면 모든 간선을 정확히 한 번(방향 그래프) 혹은 두 번(무향 그래프) 확인한다.
- 따라서 시간 복잡도는 O(|V| + |E|)가 된다.
- 인접 행렬을 사용하는 경우
- 호출 횟수는 그대로 |V|이다.
- dfs() 내부에서 다른 모든 정점을 순회하며 한 번 실행에 O(|V|)의 시간이 든다.
- 따라서 시간 복잡도는 O(|V|2)가 된다.
장점
- 출발노드에서 목표노드까지의 최단 길이 경로를 보장한다.
단점
- 경로가 매우 길 경우 탐색 가지가 급증하여 보다 많은 저장 공간을 필요로 하게 된다.
- 해가 존재하지 않으면 유한 그래프(finite graph)의 경우 모든 그래프를 탐색한 후 실패로 끝난다.
- 무한 그래프(infinite graph)의 경우 해를 차지도 못하고, 끝내지도 못한다.
Reference
Comments
CS 의 다른 글
-
HTTP 헤더 - 캐시와 조건부 요청 03 Jan 2022
-
HTTP 헤더 - 일반 헤더 26 Dec 2021
-
HTTP 상태코드 20 Dec 2021
-
HTTP 메서드 활용 17 Dec 2021
-
HTTP 메서드 12 Dec 2021
-
HTTP 기본 09 Dec 2021
-
URI와 웹 브라우저 요청 흐름 08 Dec 2021
-
인터넷 네트워크 06 Dec 2021
-
Single LinkedList 01 Oct 2021
-
ArrayList 24 Sep 2021
-
List Interface(리스트 인터페이스) 23 Sep 2021
-
자바 컬렉션 프레임워크 20 Sep 2021
-
면접 기초 질문 리스트 31 Aug 2021
-
인프라 기초 총정리 14 Aug 2021
-
하드웨어와 네트워크 기초 지식 03 Aug 2021
-
오버레이 네트워크(Overlay Network) 02 Aug 2021
-
이건 꼭 알고 가자! 면접 출제 빈도가 높은 질문들 19 May 2021
-
1분 자기소개 19 May 2021
-
백엔드 개발자 면접 / 학습내용 15 Feb 2021
-
너비 우선 탐색(breadth-first search, BFS) 22 Oct 2020
-
깊이 우선 탐색(depth-first search, DFS) 10 Oct 2020
-
크리티컬 섹션(Critical Section) 10 Sep 2020
-
삽입 정렬(Insertion Sort) 04 Sep 2020
-
선택 정렬(Selection Sort) 04 Sep 2020
-
거품 정렬(Bubble Sort) 04 Sep 2020
-
LRU 알고리즘 31 Aug 2020
-
Stack, Queue 29 Aug 2020
-
awk 명령어 사용법 24 Aug 2020
-
grep 명령어 사용법 23 Aug 2020
-
DNS의 이해 14 Aug 2020
-
대칭키와 공개키 10 Aug 2020
-
HTTP & HTTPS 10 Aug 2020